Data relationship fundamentals
Data modeling begins in App Studio’s Data objects and integrations landing page. Add Properties to the Data Model tab of either a data object or case type. If applicable, define the Property as a relationship within the Type column.
Any type of relationship can exist between any two objects regardless their type. It is imperative to define relationships observing the Build for Change guardrail. Time and money is better spent on new-opportunity development than refactoring.
Nodes and edges
An "edge" is a one-directional connection between two distinct instances, regardless of the class or type of node at each end of the edge. A "from" Person node can be the "parent" of a "to" Person node to which it is connected. The "to" node would be the "child" node of the "parent" node.
In a diagram, a node can loop back on itself. This loop only occurs when a parent-child relationship exists, and the parent and child instances differ. An edge can also exist between nodes with different classes. Because the classes are different, the same instance cannot be on each end.
For example, for three classes (Organization, Contact, and Address), the possible edges between these classes are shown in the following table:
|
Class |
Organization |
Contact |
Address |
|---|---|---|---|
|
Organization |
ParentChild |
OrgContact |
OrgAddress |
|
Contact |
None |
ParentChild |
ContactAddress |
|
Address |
None |
None |
ParentChild |
Cardinality
The term "cardinality" is derived from mathematics and applies to the drawing of an Entity Relationship Diagram (ERD) or a Unified Modeling Language (UML) diagram. Cardinality defines how the number of instances of one entity relates to the number of instances of another entity in relative terms.
The letter "M" refers to "many." The number "1" represents a single entity or the only entity.
Within an ERD or UML diagram it is possible to use numbers other than 1. Pega, though, only supports the three combinations of "1" and "M." Those three combinations are:
- 1:1
- 1:M or M:1
- M:M
Relationship types
There are three main types of relationships between entities or objects:
- Association
- Aggregation
- Composition
Aggregation is when a 1:M relationship exists, where the left side owns the right side. Duplication of right-side data, other than the foreign key that points to the left side, can exist. Deletion of the right side data is appropriate when deletion of the left side occurs. The term for this is "cascade delete."
An association is when the left side of a relationship does not own the right side. Deletion of the left side data does not justify deletion of the right side data.
An M:M relationship is an association. In a database, an association table has two foreign keys, and each key points to a different row in a table. A parent-child relationship within the same table is an association
A composition is sometimes called a "strong association." Composition is when more than two classes are strongly related. For example, a composition has an organization node at the center. An organization can have multiple contacts, addresses, parent organizations, and child organizations. A person can also be at the center of a composition. A person can have multiple addresses (such as home and work), multiple parents (such as father and mother), and multiple children.
Graph data structures
A graph is any set of relationships formed using nodes, also called “vertices,” and edges.
An edge implies direction from one node to the second node. A bidirectional relationship between two different nodes requires at least two edges.
A circular closed loop, or “cycle,” can occur when one or more edges point back to the originating node. A graph search algorithm that encounters a cycle would loop forever.
The two main types of graph data structures used in business applications are:
- Directed Acyclic Graph (DAG)
- Tree
Both data structures allow multiple child nodes. The difference is that a DAG allows a node to have multiple parent nodes. A tree allows only one parent node. For example, a “family tree” is a DAG because people have two biological parents, not one. An organization structure is a tree, typically, except when the organization structure is a matrix.
Support began for more than one built-on application in Pega 7.3. Previously a tree, application structure became a DAG. Organization hierarchy specialization implemented as a parallel application stack became possible.
Check your knowledge with the following interaction:
Data relationships in Pega Platform
Both case types and data types have a Data Model tab. A difference exists in how the Data Model tabs operate.
Case types
A data transfer object (DTO) is a self-contained composition data type. A DTO has embedded pages and page lists
A case populating its own first-level embedded pages and page lists works well. A case attempting to populate a DTO’s embedded pages and page lists is problematic. A DTO only needs a read-only View.
A case type can define the same embedded pages and page lists as a DTO data type. The DTO data type can define a Savable Data Page that can copy a case's embedded pages and page lists to itself.
The save plan for a DTO Savable Data Page can be a POST-method REST connector. The save plan could choose, instead, to persist data to tables within the database.
A receiving system of record (SOR) should define unique keys, not the sender. GUID primary keys preserve relationships between temporary storage Live Data records. A DTO Savable Data Page’s save plan can set GUID primary keys and foreign keys. Remove personal data within the case's embedded pages if security requires.
Data types
The Link- class in Pega Platform supports M:M relationships. Other examples are PegaData-OrgOrgRel, PegaData-OrgContactRel, and PegaData-ContactContactRel. What the PegaData- classes add, compared to Link-, is the notion of a relationship “role” name. The role is not just a name but also the key to the PegaData-Role class.
The PegaData-ContactOrgRel class consists of the following information:
- ContactId
- OrganizationId
- RoleId
A person can be related to the same organization with a different role. For example, someone who is both a teacher and an athletic coach at the same school.
Two association classes exist for two data types (organization and contact), which agree with the N*(N-1)/2 formula.
The Link- base class in Pega Platform attempts to be a universal association class, but it is unclear what pxLinkedRefFrom and pxLinkedRefTo are concerning a directed relationship (edge) because the Link- class does not support a Role property unlike the three PegaData *Rel classes which do support a Role property. Should a Role property be added to the Link- class, and given a value such as “ParentChild,” confusion would be eliminated. One can examine the parallel pxLinkedRefClassFrom and pxLinkedReClassfTo properties to complete the picture. If pxLinkedRefClassFrom and pxLinkedReClassfTo are the same class, do you assume that “from” is the parent and “to” is the child?
A straightforward solution is to use visual adjectives such as “left” and “right.” It is assumed that the left points to the right (such as a chart with an X-axis where time increases from left to right). Relationships are typically formed in chronological order. A parent must exist before a child can exist, for example, and an organization must exist before it can choose who its contacts are.
A hypothetical edge or M2M (many-to-many) might contain the following properties:
- LeftClass
- LeftKey
- LeftLabel
- RightClass
- RightKey
- RightLabel
- Role
- Active (inherited)
It is unnecessary to create new link/association classes whenever a data type is added to a composition if an M2M class is in use.
Consider the following example of communication networks, air travel, and delivery strategy. It is more efficient and less expensive from the provider’s perspective to use a hub/spoke network instead of a point-to-every-other-point full mesh network. With a full mesh network, the number of connections is proportional to N-squared. With a hub/spoke network, the number of connections is N. With a full mesh network, when you add a node, you must add N-1 connections. With a hub/spoke network, the system adds one connection when you add a node.
From a software perspective, a universal M2M “hub” class means that adding a new data type is just that; creating a new class for that data type. To proceed with the full mesh approach, you must create N-1 link/association classes. More classes mean more rules to maintain.
Query properties
As a best practice, design a case type to keep track of foreign keys that it uses to perform its tasks. This information is necessary for traceability (for example, information about when the case was created or updated outside the case or any historical data instance that references the case).
An historical data type can have a foreign key that points to a case. Having case-referencing historical data type instances eliminates the need for the case to store the same data within its BLOB. Doing so also improves reporting by not having to generate Index- classes using a Declare Index rule.
The question then becomes, were an M2M class to exist, does a data type need any foreign keys other than a case-referencing foreign key? And does a data type need any property that represents a page or page list query?
A data page performs the query so why not use the data page directly? When an M2M class exists, the main parameter to the query of the data page is the primary key of the data type. The M2M class knows every foreign key. The M2M class needs to know the relationship’s role and on which side, left or right, to match the data type’s primary key.
That query, however, returns only a list of M2M instances. If a data type wants a page list of opposing-class instances, then the data type defines a List data page that joins the M2M class with that opposing class. The query can filter on Active = “Y” to avoid viewing previously deactivated relationships. Data pages that return opposing class instances are also necessary when using the N-1 full mesh link/association class approach; a query is a query.
“Reference data” data types (long-lived instances such as organizations, contacts, and addresses) do not need foreign key properties because every relationship they have is defined in the M2M class.
The M2M class can support 1:M aggregation relationships in addition to M:M association relationship. The primary role of the M2M class is to facilitate a query.
The M2M class can also support a bidirectional 1:1 relationship. But if two data types have a strong coupling, foreign key properties can be defined instead. A page query is still necessary to retrieve the data. If the data is historical, then the foreign key points to what it historically pointed to at the time the historical record persisted.
Do not update historical records once resolved. Suppose historical records point to reference data, which has changed since the creation of the historical record. You need to use a Snapshot Pattern if that level of auditing is required.
The M2M class allows the cardinality between two data types to change on demand. One application might want a 1:M aggregation relationship between two data types. Another may want a M:M association relationship between the same two data types.
Data Relationship Management
Defining how a data instance can access other data instances, and for what purpose, is a start. Relationship maintenance is a concern, also.
Deactivation
If a data type can be related to any other data type, how can a data instance be "retired" after the system no longer references it? Every relationship to the instance might be deactivated, but the data instance itself remains searchable unless the value of the active property is set equal to "N."
For example, consider the Java Garbage Collection process. Java programs recover a block of memory when nothing references that block.
A job scheduler could periodically search an M2M table for keys where an active relationship no longer exists. You then need to find out the system of record for each completely inactivated key. Multiple applications might share the M2M table, and each application might not want to share its data with other applications.
It makes sense that the application that inserted the M2M data is responsible for inactivating its own data. Only the application knows whether the relationship is an aggregation or an association.
Searchability
If searching for a contact, how can you be certain, based on name, phone, and email address, that the searched contact is correct? This issue is similar to the concerns surrounding Personally Identifiable Information (PII), but in this context, you want to locate the correct person with whom the enterprise has previously interacted. A Master Data Management (MDM) problem arises when multiple "siloed" systems exist or two companies merge after an acquisition.
More information about the person is necessary (for example, the address or a company with which the person has an association) to increase the likelihood that you identify the correct person.
An autocomplete search can return combinations of information. But the autocomplete search needs a class with a property for every piece of information that the search returns. The solution is to define a database view, then associate a data type to that view.
With data stored in a "regular" database table (CustomerData schema), a List data page can execute a Connect-SQL rule-generated query that is more complex than a Report Definition can generate. Warnings are displayed as a result because the system requires an activity to use the RDB-List method.
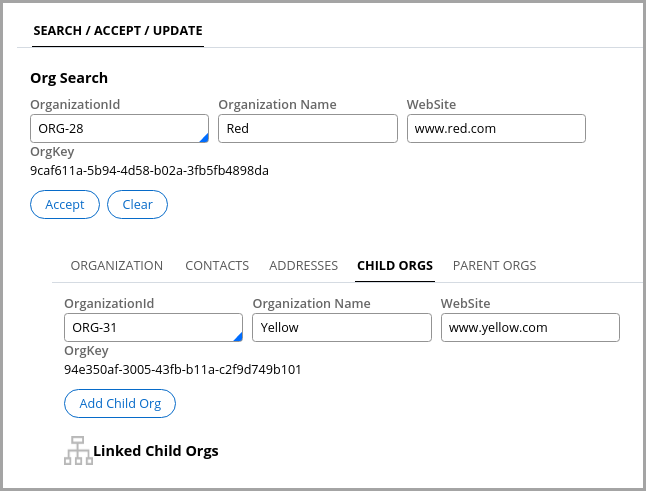
Closed-loop detection
A DAG must prevent the creation of closed loops. Suppose the following scenario.
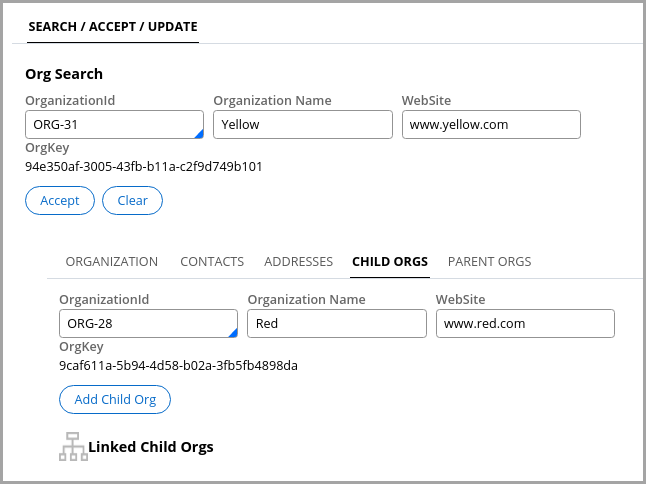
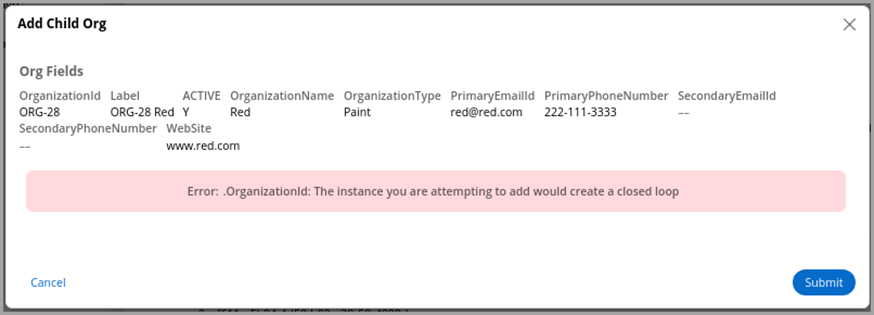
The following figure shows the Validate form for the Add Child Org flow action.
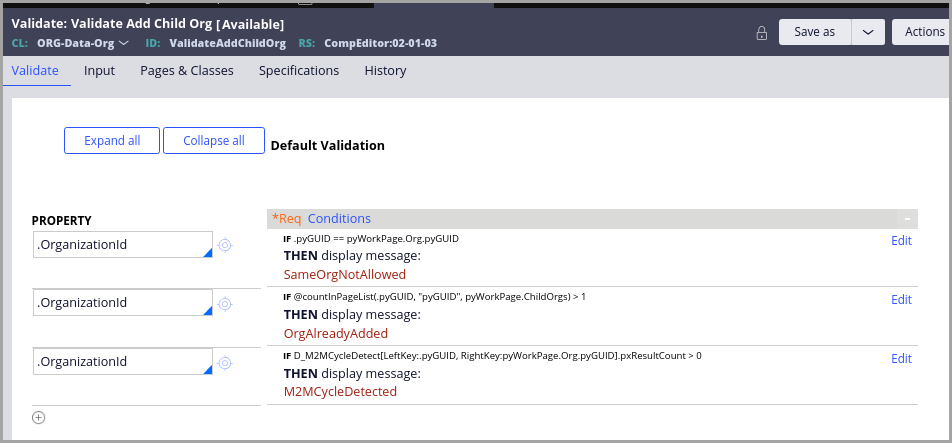
The system uses the D_M2MCycleDetect data page in the M2M class. The LeftKey and RightKey parameters are as shown below.
D_M2MCycleDetect[LeftKey:.pyGUID, RightKey: pyWorkPage.Org.pyGUID].pxResultCount > 0
When a parent organization is added, the LeftKey and RightKey parameters are reversed.
The activity that the D_M2MCycleDetect data page sources is shown in the following figure.
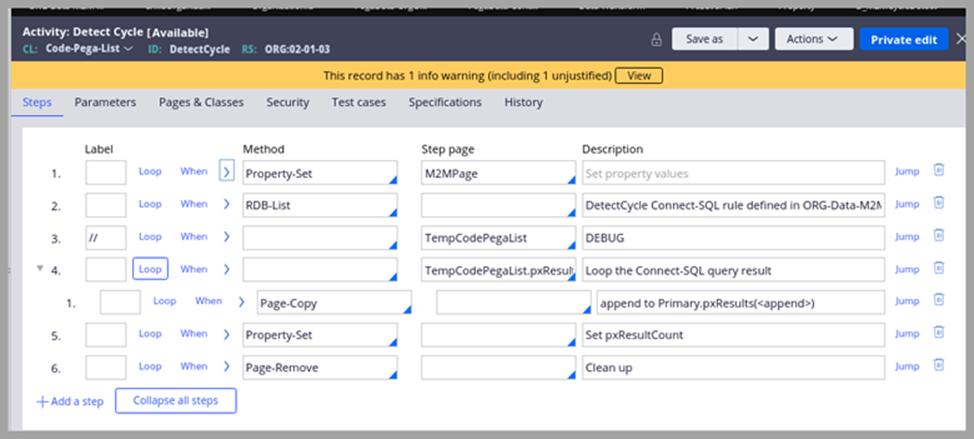
In Step 1, M2MPage properties are set using parameters.
In Step 2, the system then runs the RDB-List method against a Connect-SQL rule.
The Postgres database-specific SQL within that Connect-SQL rule is shown below.
WITH RECURSIVE search_graph(leftkey, rightkey, role, depth, cycle)
AS (
SELECT m2m.leftkey, m2m.rightkey, m2m.role, 1, m2m.rightkey = '{Asis:M2MPage.RightKey}'
FROM pr_org_data_m2m m2m
WHERE m2m.leftkey = '{Asis:M2MPage.LeftKey}'
AND m2m.role = 'ParentChild'
UNION ALL
SELECT m2m.leftkey, m2m.rightkey, m2m.role, sg.depth + 1, m2m.rightkey = '{Asis:M2MPage.RightKey}'
FROM pr_org_data_m2m m2m, search_graph sg
WHERE m2m.leftkey = sg.rightkey AND NOT cycle
)
SELECT * FROM search_graph where cycle = 'true';
AS (
SELECT m2m.leftkey, m2m.rightkey, m2m.role, 1, m2m.rightkey = '{Asis:M2MPage.RightKey}'
FROM pr_org_data_m2m m2m
WHERE m2m.leftkey = '{Asis:M2MPage.LeftKey}'
AND m2m.role = 'ParentChild'
UNION ALL
SELECT m2m.leftkey, m2m.rightkey, m2m.role, sg.depth + 1, m2m.rightkey = '{Asis:M2MPage.RightKey}'
FROM pr_org_data_m2m m2m, search_graph sg
WHERE m2m.leftkey = sg.rightkey AND NOT cycle
)
SELECT * FROM search_graph where cycle = 'true';
As a best practice, limit the value of the depth parameter. This way, if the system encounters a loop and this depth-first search fails to detect it, the code cannot loop forever.
In Step 5, the system ensures the value for the Code-Pega-List pxResultCount property is set.
Check your knowledge with the following interaction:
If you are having problems with your training, please review the Pega Academy Support FAQs.
Want to help us improve this content?