Node classification
Pega Platform™ processing can be distributed across the individual nodes in a cluster. Pega Platform is commonly deployed on servers called nodes that work together in groups called clusters. The nodes provide the resources to process browser interactions and handle background processes such as background tasks or listening for network requests.
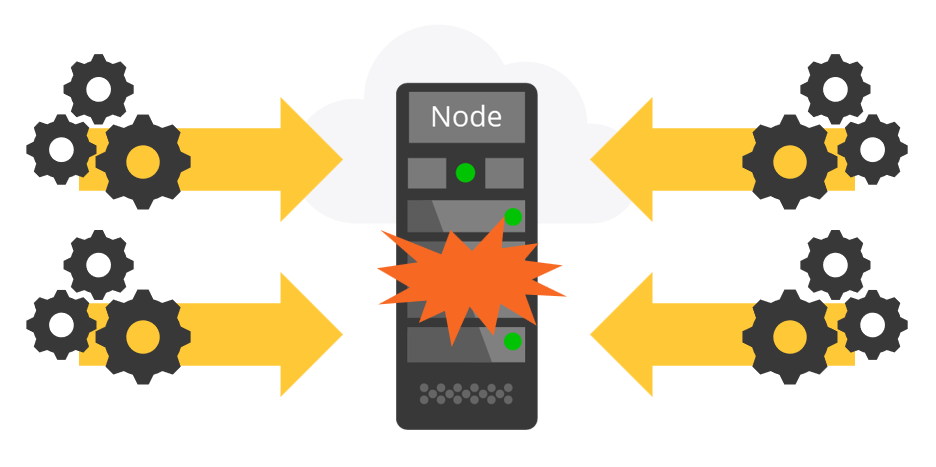
However, application performance can suffer if too many system requestors (such as users, background tasks, or listeners) attempt to perform tasks at the same time on the same node. The requested tasks compete for processing cycles and database access, which can lead to decreased performance, as shown in the following figure:
You can distribute system processes and user processes to different nodes according to the types of tasks the nodes perform. This approach is called node classification. Assigning specific tasks to specific nodes can mitigate performance issues. Distributing resources across nodes diminishes the processing burden on any single node. For example, using the node classification approach, you can designate a node for background processes and another node for users.
In the following image, click the + icons to see a breakdown of node classification:
The performance of systems with background processing can be enhanced by either classifying nodes so that jobs run on a separate system from user traffic or timing background processing to occur when users are not generally using the system. Slowdowns due to job schedulers tend to be cyclical, recurring at specific intervals and at specific times during the day. In some cases, job schedulers running at off-hours is not a good option. For example, when a global organization wants users to experience excellent performance at all times, the system does not have designated off-hours. Classifying specific nodes for resource-intensive job schedulers and queue processors may be the best solution.
In another example, listeners often respond to requests at random times. These requests may process large files that require extensive database operations that cause processing bottlenecks. Users working in the same node as the listener likely experience a performance slowdown.
Note: For more information on how to associate listeners with nodes, see Managing listeners. For more information on how to associate queue processors with nodes, see Managing Queue Processors.
Node classification with node types
Node classification allows you to define nodes according to their purpose. Node classification comprises two major tasks.
First, classify the nodes by configuring the application servers with node types. In Pega Platform, node types are JVM arguments that describe the purpose of the node. Standard node types include background processing, search, and web users. You can configure a server with one or more node types.
Note: For more information on how to create node types, see Creating node types for different purposes.
Second, in Dev Studio, you can associate job schedulers and queue processors or listeners with specific node types. For example, if you associate a job scheduler and queue processor with a Search node type, the system uses nodes that are classified as Search nodes. A job scheduler associated with a Search node type is shown in the following figure:
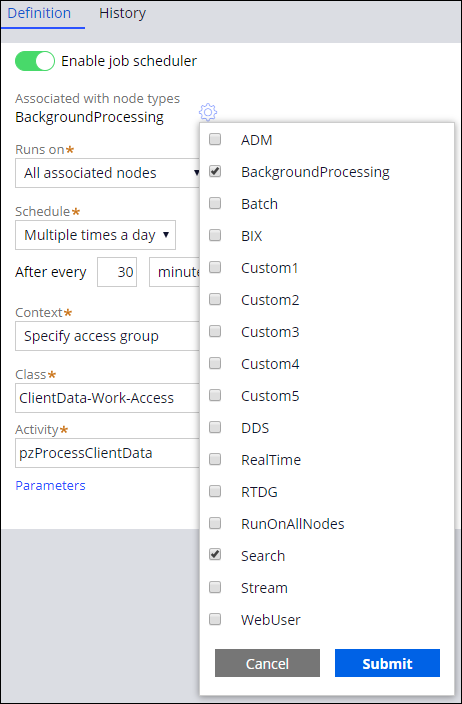
If all the nodes in a cluster are classified, a job scheduler or queue processor runs only if it is associated with at least one of the classified nodes. If you associate a job scheduler or queue processor with a node type that is not classified in the cluster, the job scheduler or queue processor runs on any untyped node based on the schedule of the untyped node. As a best practice, classify all the nodes in a cluster to consistently control the node schedules.
Note: For more information on how to create a queue processor, see Creating a queue processor Rule. For more information on how to create a job scheduler, see Creating a job scheduler rule. For more information about node classification, see Classifying nodes.
Check your knowledge with the following interaction:
This Topic is available in the following Module:
If you are having problems with your training, please review the Pega Academy Support FAQs.
Want to help us improve this content?