Building models with Pega machine learning
Archived
7 Tasks
5 mins
Beginner
English
Scenario
U+ Bank uses artificial intelligence (AI) to determine which credit card offer to show a customer on the bank’s website. To reduce the number of clients that leave the bank, the business wants to leverage the historical data that the bank has collected on customers that have churned in the past to predict which customers are likely to leave the bank in the near future. The bank wants to show the potential churners a retention offer instead of a credit card offer.
As a data scientist, your task is to create a predictive model that predicts churn. You decide to create the model using Pega machine learning.
Use the following credentials to log in to the exercise system:
|
Role |
User name |
Password |
|
Data Scientist |
DataScientist |
rules |
Your assignment consists of the following tasks:
Task 1: Create a new predictive model
Create a new predictive model, ChurnPML, using the Churn Modeling template in the Retention catagory.
Task 2: Prepare the data
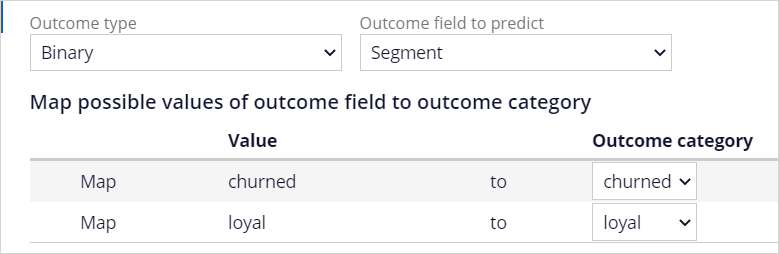
Load the data set using the historical_data.csv file. Set the type of predictors that have no predictive power, like CustomerID and OfficePhone, to Not used. Create a uniform sample that uses 100% of the data. Retain 20% for the test set and 20% for the validation set. In the Outcome definition, use a Binary outcome type and Segment as the outcome field. Map the values of the outcome field to the outcome category.
Task 3: Analyze the data
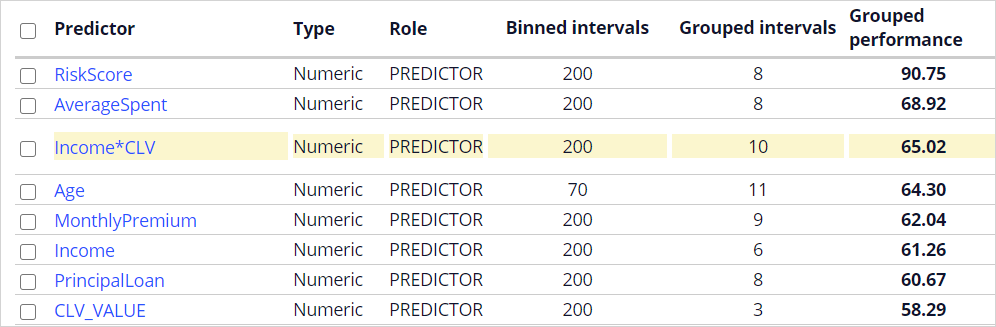
Change the role for predictors that have a grouped performance lower than 52 to ignored. Examine the trends exhibited by the best performing predictors. Create a virtual field by combining several numerical predictors and examine the trend exhibited by this new predictor.
Task 4: Develop predictive models
For predictor grouping, use the best predictor of each group. Create a new decision tree model of type ID3.
Task 5: Analyze the models
Compare the scores of the three models. Pay particular attention to Discrimination.
Task 6: Select model
Select the Regression model. Make sure all predictors are mapped to customer properties. Reclassify the classes into a loyal class and a churned class. Save the model.
Task 7: Test the model
Run the model using the Troy data transform. Troy has a high churn risk. Re-run the model using the Barbara data transform. Barbara has a low churn risk. Finally, run the model on the CustomerBatch data set and notice the number of customers that are predicted to churn.
Challenge Walkthrough
Detailed Tasks
1 Create a predictive model
- Download and extract the historical_data.csv file.
- Log in as a Data Scientist with user name DataScientist and password rules.
- In the navigation pane on the left, click Intelligence > Prediction Studio > Models.
- Click New > Predictive model.
- In the New predictive model dialog box, in the Name field, enter ChurnPML.
- In the Category list, select Retention.
- In the Template list, select Churn Modeling.
- Click Start.
2 Prepare the data
- In the Source selection section, click Choose File and select the historical_data.csv file.
- Check the data, and then click Next.
- For the CustomerID and ACCOUNT_ID fields, change the type to Not used.
- Click Next.
- In the Outcome definition section, in the Model type list, select Binary.
- In the Outcome field to predict, select Segment.
- In the Outcome category list for churned, select churned.
- In the Outcome category list for loyal, select loyal.
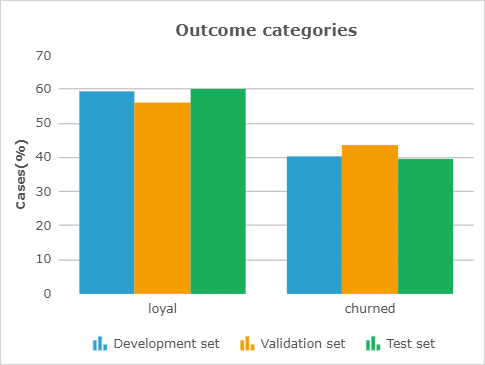
- Check the number of cases in the development, validation, and test sets.
- Click Next.
3 Analyze the data
- In the list of predictors, click RiskScore and examine the grouping for this predictor.
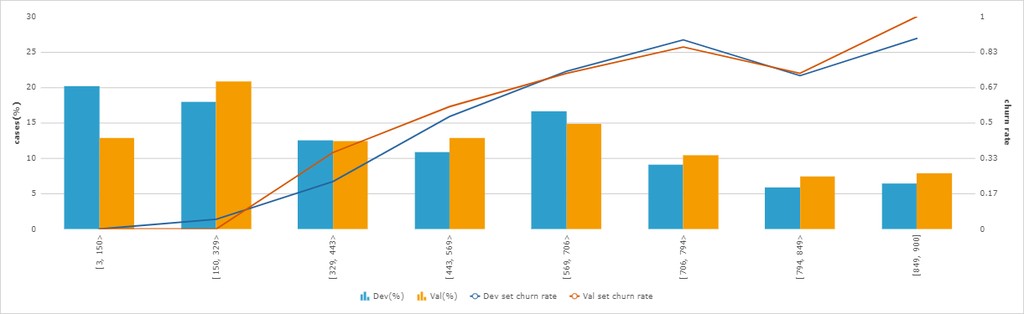
- Click Cancel.
- Click New virtual field.
- In the Virtual field dialog box, in the Name field, enter Income*CLV.
- Click Fields, select Income, and then click Insert.
- Repeat this field selection step and build up the expression: Income * {CLV_VALUE}.
- Click Save & close.
- Confirm that the newly created predictor outperforms the two original predictors.
- Click Next.
4 Develop predictive models
- In the Model development section, select Use best of each group.
- Click Next.
- In the Model creation section, select Decision tree from the Create model list.
- Click Create model.
- Select ID3.
- Click Create.
- Examine the model created.
- Click Submit to save the model.

- Click Next.
5 Analyze the models
- Ensure that the check boxes next to all models are selected.
- Click Analyze charts.
- Select the Discrimination tab and examine the results.
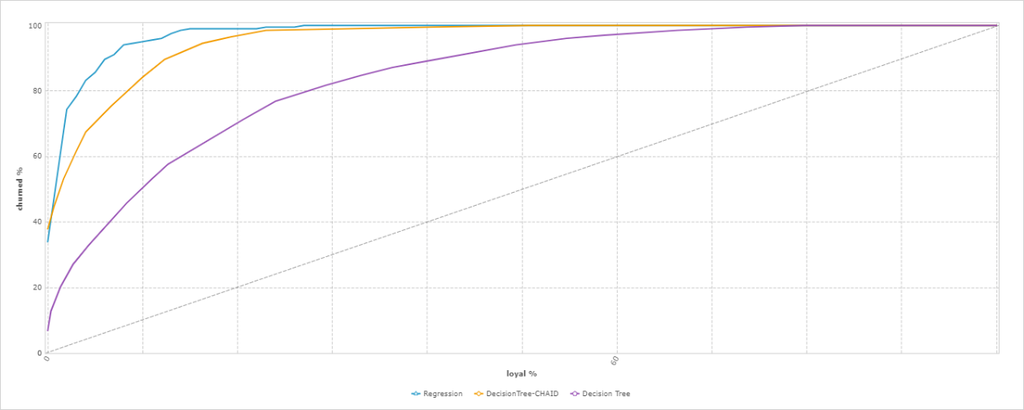 Note: The regression model outperforms both decision tree models as it has the largest area under the curve (AUC). However, before you choose a model you should also consider the number of predictors required by the model. Under certain circumstances you may decide to select a lower performing predicting model but one with fewer predictors. Note that all models perform very well with a value around 90.
Note: The regression model outperforms both decision tree models as it has the largest area under the curve (AUC). However, before you choose a model you should also consider the number of predictors required by the model. Under certain circumstances you may decide to select a lower performing predicting model but one with fewer predictors. Note that all models perform very well with a value around 90.
- In the upper left, click the arrow next to Model analysis charts.

- Click Next. Here, you can analyze the score distribution.
- Click Next. Here, you can analyze class comparison.
- Click Next.
6 Select the model
- Select the Regression model.
- Click Finish.
- On the Model tab, in the Expected score distribution section, click between Result6 and Result7 in the score distribution chart.
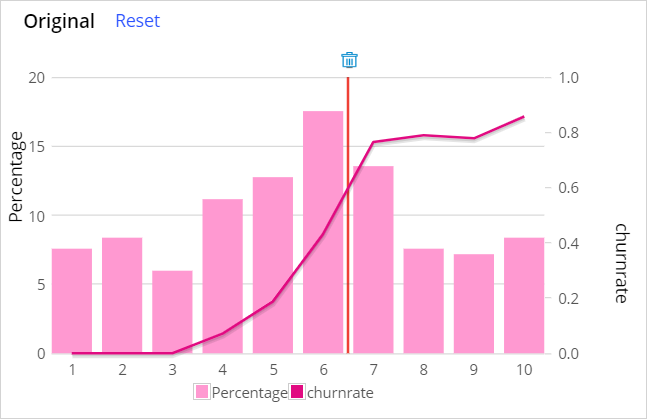
- Under Classification groups, rename class 1-6 as loyal and Class 7-10 as churned.
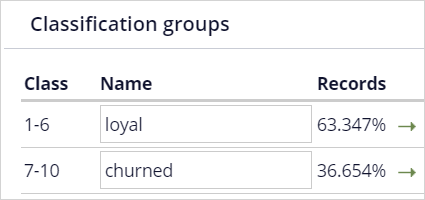
- Click the Mapping tab and ensure all predictors are mapped to the appropriate customer fields.
- Click Save.
7 Test the model
- In the top right, click Run.
- In the Run predictive model dialog box, in the Inputs section, select data transform Troy as the data source.
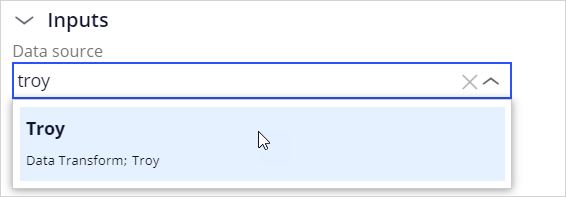
- Click Run and scroll down to the Outputs section. Verify that the result for Troy is churned.

- Re-run the model with data transform Barbara as the data source.
- Verify that the result for Barbara is loyal.

- On the Batch run tab, select CustomerBatch as the data source.
- Click Re-run.
- For the output, select Results.
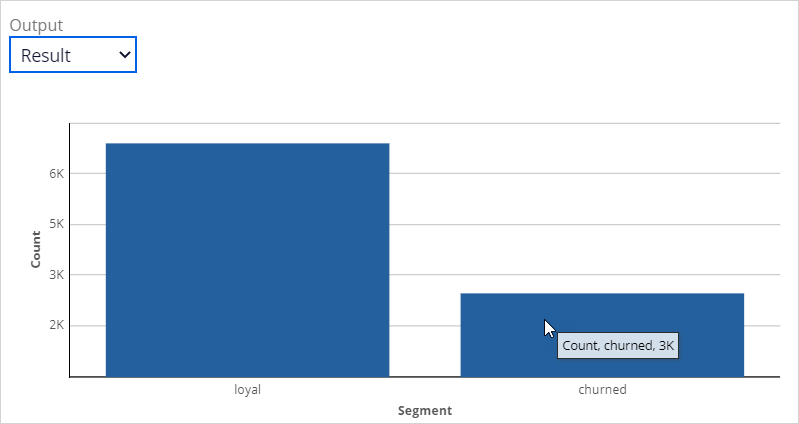
- Notice that model predicts that roughly 30% of the 10K customers in the data set is likely to churn.