Procesador de colas y programador de trabajo
Pega Platform™ admite varias opciones para el procesamiento en segundo plano. Puede usar los procesadores de cola, programadores de trabajo agentes estándares y avanzados, acuerdos de nivel de servicios (SLA), figuras de espera y receptores para diseñar procesamiento en segundo plano en la aplicación.
Nota: Para una mejor escalabilidad, facilidad de uso y un procesamiento en segundo plano más rápido, use las reglas del programador de trabajos y del procesador de colas en lugar de los agentes.
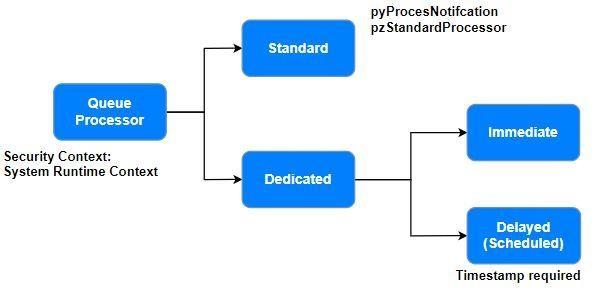
Procesador de colas
Una regla de procesador de colas es un proceso en segundo plano interno que puede configurar para la gestión de colas y el procesamiento de mensajes asincrónicos. Use reglas de procesamiento de cola estándares para la gestión de colas simple o escenarios de rendimiento total de procesamiento bajo, o use reglas de procesamiento de cola dedicadas para rendimiento total de procesamiento de mayor escalabilidad y procesamiento personalizado o retrasado de mensajes.
Pega Platform ofrece muchos procesadores de cola estándares predeterminados que se pzStandardProcessor disparan de manera interna a los mensajes de cola cuando se escoge el estándar como opción en la sección de tipo de cola del método Queue-For-Processing o en la figura de ejecución en segundo plano. Se debe aprobar una actividad personalizada. La disponibilidad de esta regla se encuentra configurada para Final para restringir cambios. Este procesador de cola es inmediato y no se puede usar en escenarios en los que se necesita un proceso retrasado.
Una regla de procesador de cola le permite concentrarse en la configuración de las operaciones específicas que se ejecutan en segundo plano. Pega Platform ofrece funcionalidades integradas para la gestión de errores, para poner en cola y retirar de cola, y puede confirmarse condicionalmente cuando se usa un procesador de cola. Los procesadores de cola se usan de manera frecuente en una aplicación que deriva de un framework común o que usa la propia Pega Platform.
Todos los procesadores de cola son resueltos con reglas respecto al contexto que se especifica en el contexto de tiempo de ejecución del sistema. Cuando configure el método Queue-For-Processing en una actividad, o el paso de ejecución en segundo plano en una etapa, puede especificar un grupo de acceso alternativo. Es posible para la actividad que el procesador de cola se ejecute con el fin de cambiar el grupo de acceso. Un ejemplo es la pzInitiateTestSuiteRun actividad ejecutada por el pzInitiateTestSuiteRun procesador de cola denominada “Rule-Test-Suite”.
Use reglas de procesamiento de cola estándares para la gestión de colas simple o procesadores de cola dedicados para el procesamiento personalizado o retrasado de mensajes. Si define un procesador de cola como retrasado, defina la fecha y hora cuando se conecta por medio del método Queue-For-Processing o la figura inteligente de ejecución en segundo plano.
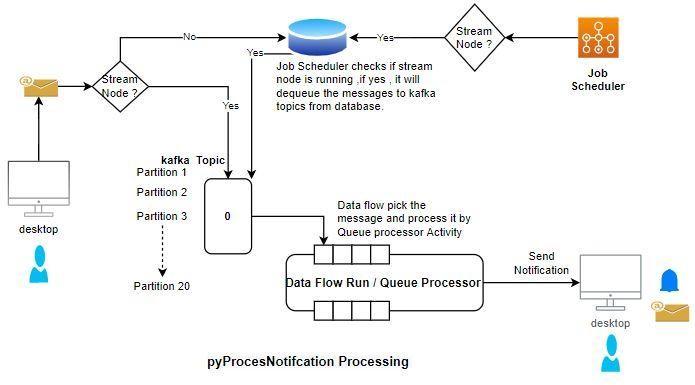
Las colas son multihilos y se comparten a través de todos los nodos. Cada procesador de cola puede procesar mensajes a través de 20 particiones, lo que significa que las reglas de procesador de cola pueden admitir hasta 20 hilos de procesamiento separados de manera simultánea sin problemas. El aprovechamiento de varios procesadores de cola en nodos separados para procesar los elementos de una cola también puede mejorar el rendimiento.
Por ejemplo, supongamos que necesita enviar alguna notificación. En ese caso, el procesador de cola pyProcessNotifcation se usa como se muestra en la imagen siguiente:
El rendimiento tiene dos dimensiones: el tiempo de procesamiento de un mensaje y el rendimiento total del mensaje. Estas se pueden mejorar realizando las siguientes acciones:
- Optimizar la actividad para reducir el tiempo de procesamiento de un mensaje. El tiempo de procesamiento de un mensaje depende de la cantidad de trabajo realizado por la actividad de procesamiento.
- Potencie el rendimiento de los mensajes de la siguiente manera:
- Escale horizontalmente aumentando la cantidad de nodos de procesamiento. Esta configuración se aplica solo a usuarios que trabajan desde las instalaciones. Se requiere un espacio aislado más amplio para Pega Cloud® Services.
- Escale verticalmente la capacidad incrementando el número de hilos por nodo, hasta 20 hilos por clúster.
Tan pronto como se crea un procesador de cola, un tema que corresponde a este procesador se crea en el servidor Kafka. En función del número de particiones mencionadas en el archivo server.properties, se crea el mismo número de carpetas en el tomcat\Kafka-data folder.
Es necesario que se esté ejecutando al menos un nodo de flujo para que los mensajes se incluyan en la cola hacia el servidor Kafka. Si no define un nodo de flujo en un clúster, los elementos se incluyen en la cola que va a la base de datos, y luego se procesan cuando un nodo de flujo se encuentra disponible.
Procesadores de cola predeterminados
Pega Platform proporciona tres procesadores de cola predeterminados.
pyProcessNotification
El procesador de cola pyProcessNotification les envía notificaciones a los clientes y ejecuta la pxNotify actividad para calcular la lista de recipientes, los mensajes, o el canal. Los canales posibles incluyen un correo electrónico, una notificación por medio de un dispositivo, o una notificación automática.
pzStandardProcessor
Puede usar el pzStandardProcessor procesador de colas para procesos asincrónicos estándares cuando:
- el procesamiento no necesita alto rendimiento, o los recursos de procesamiento se pueden retrasar levemente,
- se aceptan comportamientos de cola predeterminados y estándar.
Este procesador de cola se puede usar para tareas como el envío de cada cambio de estado a un sistema externo. Se puede usar para ejecutar procesamientos en bloque en segundo plano. Cuando el procesador de cola resuelve todos los elementos de la cola, usted recibe una notificación sobre el número de intentos fallidos y logrados.
pyFTSIncrementalIndexer
El procesador de cola pyFTSIncrementalIndexer realiza indexado progresivo en segundo plano. Este procesador de cola coloca objetos de trabajo, de datos y de reglas en el subsistema de búsqueda cuando los crea o los cambia, lo cual colabora con la búsqueda actualizada de datos y refleja de manera precisa el contenido de la base de datos.
Programador de trabajos
Use una regla del programador de trabajos cuando no haya un requerimiento de poner en cola una tarea recurrente. A diferencia de los procesadores de cola, el programador de trabajos debe decidir qué registros procesar y establecer el contexto de la página del paso para cada uno antes de trabajar con ese registro. Por ejemplo, supongamos que necesita generar estadísticas cada medianoche para la creación de reportes. En ese caso, el resultado de una definición de reportes puede determinar la lista de elementos que se deben procesar. El programador de trabajos debe entonces operar en cada elemento de la lista.
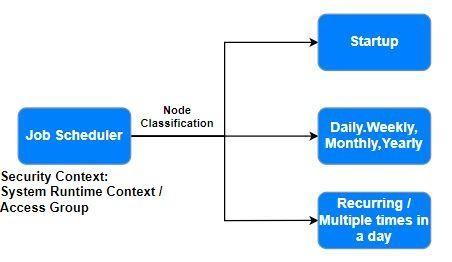
Si se necesita cualquier contexto específico para una actividad, seleccione Specify access group (Especificar grupo de acceso) para proporcionar el grupo de acceso.
Si se necesita contexto de tiempo de ejecución del sistema para una actividad, (por ejemplo, usar el mismo contexto para el programador de trabajo y la resolución de actividades), seleccione Use System Runtime Context (Utilizar el contexto de tiempo de ejecución del sistema)..
Un programador de trabajo puede ejecutarse en uno o más nodos en un clúster o cualquier nodo específico de un clúster. Para ejecutar varios programadores de trabajo de manera simultánea, configure el número de hilos para el grupo de trabajo de hilos del programador de trabajo modificando el archivo prconfig.xml. El valor predeterminado es 5. El número de hilos debería ser igual al de programadores de trabajo que se ejecutan de manera simultánea.
A diferencia de los procesadores de cola, un programador de trabajos debe decidir si es necesario bloquear un registro. También debe decidir si es necesario confirmar registros que se han actualizado usando Obj-Save. Si un programador de trabajos crea un caso o abre uno con un bloqueo y ocasiona que se mueva a una nueva asignación o se complete su ciclo de vida, el programador de trabajos no necesita emitir una confirmación.
Programadores de trabajos predeterminados
Pega Platform proporciona muchos procesadores de trabajos que pueden ser útiles en la aplicación.
Limpiador de nodos
El limpiador de nodos elimina bloqueos caducos y reportes obsoletos de versiones de módulos.
De manera predeterminada, el programador de trabajos del limpiador de nodos (pyNodeCleaner) ejecuta la Code-pzNodeCleaner actividad en todos los nodos del clúster.
Limpiador de clúster y base de datos
De manera predeterminada, el programador de trabajos del clúster y la base de datos (pyClusterAndDBCleaner) ejecuta la Code-.pzClusterAndDBCleaner actividad en solo un nodo en el clúster cada 24 horas para tareas de mantenimiento. Este trabajo purga los siguientes elementos:
- registros antiguos de las tablas de registros,
- solicitantes inactivos por 48 horas,
- datos de pasivación para solicitantes caducos (limpieza de portapapeles),
- bloqueos caducos,
- datos de estado del clúster con antigüedad mayor a 90 días.
Estado de nodo de persistencia y del clúster
pyPersistNodeState guarda el estado del nodo como inicio de nodo.
El pyPersistClusterState programador de trabajos guarda los datos del estado del clúster una vez por día.
El pzClusterAndDBCleaner programador de trabajos elimina datos de estado del clúster con antigüedad mayor a 90 días.
Agente estándar
Caution: Considere usar un programador de trabajos o un procesador de cola en lugar de un agente.
Los agentes estándares son preferibles cuando tiene elementos que se encuentran en cola para ser procesados. Un agente estándar le permite concentrarse en la configuración de las operaciones específicas que se deben ejecutar. Pega Platform ofrece funcionalidades integradas para la gestión de errores, para poner en cola y retirar de cola, y se confirma cuando se usa un agente estándar.
De forma predeterminada, los agentes estándares se ejecutan en el contexto de seguridad de la persona que puso la tarea en cola. Este esquema puede ser ventajoso en los casos en que los usuarios con diferentes grupos de acceso aprovechan el mismo agente. Los agentes estándares se usan de manera frecuente en una aplicación con muchas implementaciones que derivan de un framework común o en agentes predeterminados que proporciona Pega Platform. La configuración de grupo de acceso en una regla de agente se aplica solamente a agentes avanzados que no se encuentran en cola. Para ejecutar siempre un agente estándar en un contexto de seguridad determinado, debe cambiar el grupo de acceso en cola anulando la System-Default-EstablishContext actividad e invocando el setActiveAccessGroup() método de java dentro de esa actividad.
Las colas se comparten a través de todos los nodos. El aprovechamiento de varios agentes estándares en nodos separados para procesar los elementos de una cola también puede mejorar el rendimiento.
Tip: Hay muchos ejemplos de agentes predeterminados que usan el modo estándar. Un ejemplo es el agente que procesa SLAs ServiceLevelEvents en el Pega-ProCom ruleset.
Agente avanzado
Use agentes avanzados cuando no haya un requerimiento de puesta en cola y de realización de una tarea recurrente. Los agentes avanzados también se pueden usar cuando se necesitan procesamientos de cola más complejos. Cuando los agentes avanzados realizan el procesamiento en elementos que no se encuentran en cola, deben determinar el trabajo que debe realizarse. Por ejemplo, si necesita generar estadísticas cada medianoche para la creación de reportes, el resultado de una definición de reportes puede determinar la lista de elementos que se deben procesar.
Tip: Muchos ejemplos de agentes predeterminados usan el modo avanzado, incluido el agente de columna de propagación automática pxAutomaticColumnPopulation en Pega-ImportExport.
Cuando un agente avanzado usa las colas, todas las operaciones de cola ocurren en la actividad del agente.
Tip: El agente predeterminado ProcessServiceQueue en el Pega-IntSvcs ruleset es un ejemplo de un agente avanzado que procesa elementos en cola.
Cuando se ejecuta una configuración multinodo, configure programas de agentes para que los agentes avanzados coordinen sus esfuerzos. Para coordinar los agentes, seleccione la configuración avanzada Run this agent on only one node en un tiempo y Delay next run of agent across the cluster by specified time period.
Agentes predeterminados
Cuando se instala inicialmente Pega Platform, se configuran muchos agentes predeterminados con el fin de que se ejecuten en el sistema (similar a servicios configurados para que se ejecuten en un sistema operativo de la computadora). Revise y ajuste las configuraciones de los agentes en un sistema de producción porque hay agentes predeterminados que:
- No son necesarios para la mayoría de las aplicaciones porque los agentes implementan características históricas o de uso muy esporádico.
- No debe ejecutarse en la producción.
- Se ejecutan en momentos inapropiados de manera predeterminada.
- Se ejecutan más frecuentemente de lo necesario, o con una frecuencia insuficiente.
- Se ejecutan en todos los nodos de manera predeterminada, pero deberían hacerlo solo en uno.
Por ejemplo, de manera predeterminada, hay varios agentes configurados para ejecutar el Pega-DecisionEngine en el sistema. Desactive estos agentes si el proceso de decisión no corresponde a las aplicaciones. Active algunos agentes solo en un entorno de desarrollo o de control de calidad, como los agentes Pega-AutoTest. Algunos agentes están diseñados para ejecutarse en un nodo dentro de una configuración multinodo.
Para una revisión completa de los agentes y su configuración, consulte Agentes y programas de agentes. Dado que los agentes se encuentran en rulesets bloqueados, no se pueden modificar. Para cambiar la configuración de estos agentes, actualice los programas de agentes que se generan desde la regla de agentes.
If you are having problems with your training, please review the Pega Academy Support FAQs.
¿Quiere ayudarnos a mejorar este contenido?