High availability
High availability refers to the capacity of a system to function continuously without interruption for a predetermined time. High availability helps ensure that a system meets a set standard for operational performance. A high-availability architecture is a strategy to eliminate process and service breakdowns. Application outages can be costly to organizations. The organization loses business when the application is unavailable and might be subject to penalties and fines. An unplanned application outage can also damage the reputation of the organization.
Before implementing highly available systems, you must carefully plan and evaluate. All components must meet the specified availability level before planning, for example, a system. The ability to back up and failover data is crucial for high-availability systems to achieve availability objectives. You must also carefully consider the data storage and access technology that system designers use.
Design for high availability
Apply the following principles when designing high-availability systems:
-
Avoid a single point of failure. If an application has only a single database in place, the entire system can fail in the event of database failure. This event is called the single failure point. So, a backup database should always be in a passive place with a database copy from an active database. Copy the database every five minutes to a passive node. You can lose up to five minutes of data. Here, the copy action is the single point of failure.
-
Ensure reliable crossover. If a node fails, the system must switch from the failed node to a backup node without losing data. This process, known as failover, should be seamless to maintain system availability.
-
Ensure the detectability of failures. Failures must be visible; ideally, systems should have built-in automation to handle the failure independently. Include built-in mechanisms for avoiding common-cause failures, where two or more systems or components fail simultaneously from the same cause.
Configuration of high availability in Pega Platform
In Pega Platform, the system achieves high availability through the configuration of multiple nodes in a cluster. If one node fails, the other nodes can take over and continue to provide uninterrupted service. The following process discusses how you can configure nodes for high availability in Pega Platform:
- Install and configure Pega clusters: Before configuring nodes for high availability, you must install and configure Pega Platform on each node. Ensure that all nodes are running the same version of Pega Platform and have the same configuration settings. Clustering involves organizing two or more Pega Platform servers to work together, which provides higher availability, reliability, and scalability than a single server. The application servers are in the cloud and must dynamically allocate servers to support increased demand.
Pega Platform servers support redundancy among various components, such as connectors, services, listeners, and search. The exact configuration varies based on the specifics of the applications in the production environment.
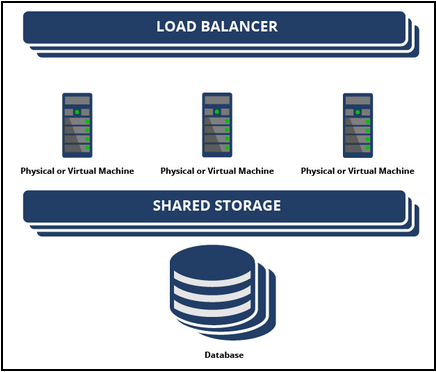
- Configure load balancer: The system uses a load balancer to distribute incoming requests across multiple nodes in a cluster, as shown in the following figure. Configure the load balancer to distribute requests evenly across all nodes in the cluster, which ensures that no single node is overloaded with requests.
- Configure database: Configure the database to support high availability. Use a database that supports clustering or replication. This configuration helps ensure that if one database server fails, another server can take over and continue to provide service.
- Configure nodes: Configure each node to communicate with the load balancer and the database. Ensure that each node has the same configuration settings, including security, logging, and performance.
- Configure highly available integration services: Integration services are critical components of any Pega Platform application and help to maintain the performance and reliability of the application.
- Configure session affinity for slow drain: Session affinity and the issue of slow drain are both important concepts in the context of load balancing and the management of server pools, especially in environments where high availability and performance are critical. Understanding both can help in designing more efficient and resilient systems. Session affinity, also known as sticky sessions, ensures that all requests from a specific client go to the same server during a session in load-balanced environments. This process is particularly important for applications that maintain session state information (such as login sessions and shopping carts) on the server side. Without session affinity, the system could route a client's subsequent requests to different servers, potentially leading to inconsistencies if the session state is not shared across the servers.
Slow drain is a condition where a server in a pool starts to process requests more slowly than its peers. It can happen for various reasons, such as hardware malfunctions, software bugs, resource contention, or network issues. Slow drain scenarios are problematic because they can lead to increased response times, imbalanced load, and session affinity impact. Manage slow drain in session affinity contexts by performing regular health checks, dynamic load rebalancing, and adjusting the distribution of requests based on server response times and health, reducing the impact of slow-draining servers, session state management Implementing a shared session state mechanism (like in-memory data grids or database-backed sessions) can help minimize the dependency on a single server for session information, which makes it easier to reroute traffic away from slow servers without losing session continuity.
While session affinity improves application performance by ensuring consistency in stateful communications, it can also introduce challenges, particularly in the presence of slow-draining servers. Effective management strategies, including comprehensive monitoring and dynamic load balancing, are essential to mitigate these issues and maintain high system performance and reliability.
- Configure shared file storage: The system stores session data for users in shared storage in the event of failover or server quiesce. The shared storage helps stateful application data to move between nodes. Pega Platform supports a shared storage system, such as a shared disk drive, a Network File System, or a database. All three options require read-write access for Pega to write data. By default, Pega Platform uses database persistence in a high-availability configuration. If organizations select a different shared storage system, they must ensure that the Shared Storage integrates with Pega Platform. The implementation of the CustomPassivationMechanism plugin is required to use a custom passivation mechanism. It is essential to configure shared storage to support quiescing and crash.
- Configure highly available deployments for application server maintenance for updates.
- Test high availability: Test the high availability configuration by simulating a node failure. You can shut down one of the nodes and verify that the other nodes continue to provide uninterrupted service.
For more information about high availability configuration, see Deploying a highly available system.
Check your knowledge with the following interaction:
This Topic is available in the following Module:
If you are having problems with your training, please review the Pega Academy Support FAQs.
Want to help us improve this content?