Case processing
Case processing
Requestors execute the majority of case processing in Pega Platform. Each requestor executes within its own Java thread. The separate Java threads allow multiple requestors to perform actions in parallel. The most common requestor types are initiated by Services, Agents, or different users logging on to the system to process cases.
The case design determines how efficiently the case is processed. An efficient case design accounts for steps or processes that can be performed in parallel by separate requestors. One example is leveraging subprocesses to gain approval from different users. Each approval process is performed by separate requestors. A more complex example is queuing tasks to a standard agent in a multinode system. There are limitations to this type of parallel processing. Limitations differ with the case configuration and the type of processing implemented.
The two major types of parallel processing options are same-case processing and child case (subcase) processing.
Same-case processing
Same-case processing occurs when multiple assignments associated with the same case are created. Each assignment is initiated through a subflow (subprocess) that is different from the parent flow (process). Multiple assignments for a single case are initiated through Split Join, Split For Each, or Spin-off subprocesses. The Split Join and Split For Each subprocesses pause and then return control to the main flow, depending on the return conditions specified in the subprocess shape. The Spin-off subprocess is not meant to pause the main flow as it is an unmanaged process.
All of these subprocess options may result in multiple assignments being created, leading to different requestors processing the case (assuming they are assigned to different users). One limiting factor is locking. The default case locking mechanism prevents multiple users from processing (locking) the case at the same time. This has been alleviated in the Pega Platform with the introduction of optimistic locking. Optimistic locking allows multiple users to access the case at the same time, and only locking the case momentarily when completing the assignment. The drawback is that once the first user has submitted changes, subsequent users are prompted to refresh their cases prior to submitting their changes. The probability of two requestors accessing the case at the same time is low, but the designer should be aware of this possibility and the consequences, especially in cases where the requestor is a nonuser.
Child case (subcase) processing
The primary difference between chld case (subcase) and same-case processing is that one or more child cases are involved. The processes for each child case may create one or more assignments for each child case. Locking can be a limiting factor when processing these assignments. If the default locking configuration is specified for all child cases, then all the related cases including the top-level case are locked while an assignment in any child case is performed. This can be alleviated by selecting the Do Not Lock Parent configuration in the child case types. Locking is a significant difference between subprocess (subflow) and child case (subcase) parallelism.
Tip: With the correct locking configuration, simultaneous processing may take place without interruption for child cases (subcases), whereas a possibility exists for interruption when subprocesses (subflows) are involved.
This behavior must be accounted for, especially when automated tasks such as agents are involved. A locked top-level case may prevent the agent from completing its task, and error handling must be incorporated, allowing the agent to retry the task later on. If a design leveraging child cases with independent locking was used such that the agent operated on the child case, it minimizes the possibility of lock contention. In general, lock child cases independently of the top-level case unless there is a reason for also locking the top-level case.
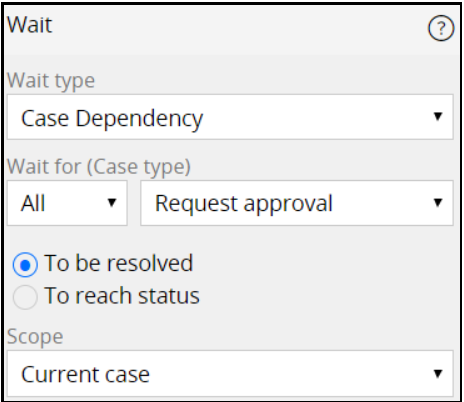
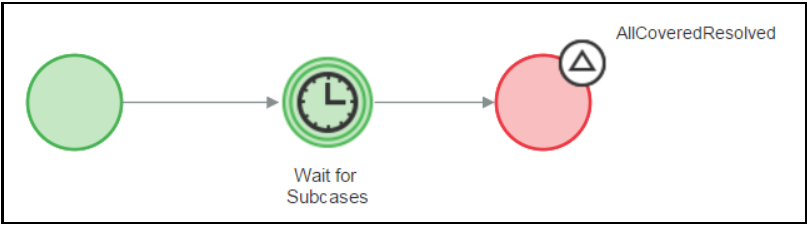
When waiting for the child cases to complete processing, a wait step is used to pause the top-level case. If multiple child cases of the same type are involved, you configure the same wait shape to allow the top-level case to proceed after all those child cases are resolved or reach a specific status.
If different types of child cases are involved, a ticket is used in conjunction with the wait shape to allow the top-level case to proceed only after all child cases, regardless of their type, are completed. The AllCoveredResolved ticket is used and is triggered when all the covered child cases (subcases) are resolved. You configure the ticket in the same process (flow) as the wait shape, and you place the ticket in the process (flow) at the location at which processing should continue. Configure the wait shape as a timer with a duration longer than the time to raise the ticket.
Child case and subprocess comparison
You have many factors to consider when deciding on a suitable case design. The following table summarizes some advantages of leveraging a design incorporating multiple cases or child cases (subcases).
| Factor | Consideration |
|---|---|
| Security | Class-based security offers more options for security refinement using multiple cases. Data security increases as child cases only contain data pertinent to their case. |
| Reporting | Reporting on smaller data sets may be easier and offer potential for performance increase (the may be a disadvantage if a join is required). |
| Persistence | You have the ability to persist case data separately. |
| Locking | You have the ability to lock cases separately and process them without interruption (significant in cases involving automated processing). |
| Specialization | This can be extended or specialized with a class or leverage Case Specialization feature. |
| Dependency Management | Case processing can be controlled through the state of top-level or child cases. |
| Performance | There is pure parallel processing since separate cases may be accessed using separate requestors. |
| Ad hoc processing | You can leverage the ad hoc case processing feature. |
Advantages of a single case design involving only subprocesses are listed in the following table.
| Factor | Consideration |
|---|---|
| Data | Data is readily available; no replication of data is necessary. |
| Reporting | All data is readily accessible for reports. |
| Attachments | All attachments are readily accessible (additional configuration is required for child cases). |
| Policy Override | Implementing this feature is easier. Managing “Suspend work” when multiple cases are involved is more complex. |
If you are having problems with your training, please review the Pega Academy Support FAQs.
Want to help us improve this content?