Background processing options
Background processing options
Pega Platform™ supports several options for background processing. You can use the Queue Processor rule, standard and advanced agents, the Job Scheduler rule, service-level agreements (SLAs), wait shape listeners, and data flows to design background processing in your application.
Note: Only leverage Standard and Advanced Agents if specific scenarios can not be handled through the queue processor and job scheduler.
Queue processor
The Queue Processor rule allows you to focus on configuring the specific operations to perform in the background. Pega Platform provides built-in capabilities for error handling, queuing and dequeuing, and commits when using a queue processor. Queue processors are often used in an application that stems from a common framework or used by the Pega Platform itself.
All queue processors are rule-resolved against the context specified in the System Runtime Context. When configuring the Queue-For-Processing method in an activity, or the Run in Background step in a stage, it is possible to specify an alternate access group. It is also possible for the activity that the queue processor runs to change the Access Group. An example is the Rule-Test-Suite pzInitiateTestSuiteRun activity executed by the pzInitiateTestSuiteRun Queue Processor.
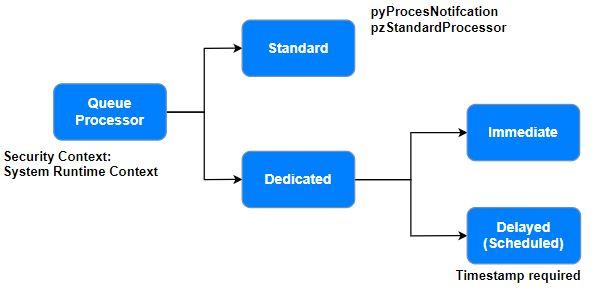
Use standard queue processors for simple queue management or dedicated queue processors for customized or delayed message processing. If you define a queue processor as delayed, define the date and time while calling through the Queue-For-Processing method or a Run in Background smart shape.
Queues are multi-threading and shared across all nodes. Each queue processor can process messages across 20 partitions, which means that Queue Processor rules can support up to 20 separate processing threads simultaneously with no conflict. Throughput can also be improved by leveraging multiple queue processors on separate nodes to process the items in a queue.
For example, suppose you have to send any notification. In that case, the pyProcessNotifcation queue processor is used as shown in the following:
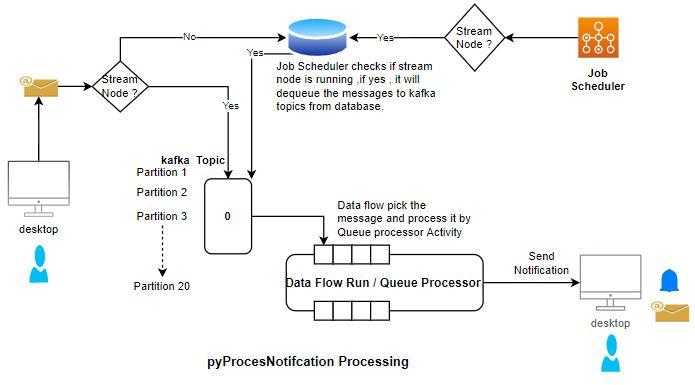
Performance has two dimensions: time to process a message and total message throughput. You can increase total message throughput by performing one of the following actions:
- Time to process a message depends on the amount of work done by the processing activity. Optimize the activity to reduce the time to process a message.
- Enhance message throughput in the following ways:
- Scale out by increasing the number of processing nodes.
- Scale up by increasing the number of threads per node up to 20 threads per cluster.
Job scheduler
Use the Job Scheduler rule when there is no requirement to queue a reoccurring task. Unlike queue processors, the job scheduler must decide which records to process and establish each record’s step page context before performing work on that record. For example, suppose you need to generate statistics every midnight for reporting purposes. In that case, the output of a report definition can determine the list of items to process. The job scheduler must then operate on each item in the list.
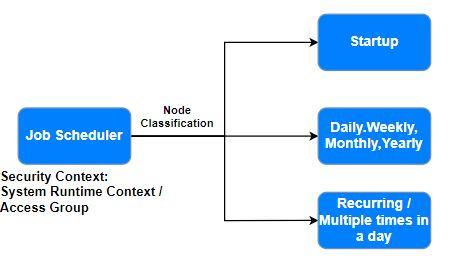
If any specific context is required for an activity, then select Specify access group to provide the access group.
If System Runtime Context is required for ab activity (for example, use the same context for the job scheduler and activity resolution), then select Use System Runtime Context.
A job scheduler can run on all nodes in a cluster or if any specific one node in a cluster. To run multiple job schedulers simultaneously, configure the number of threads for the Job Scheduler thread pool by modifying the prconfig.xml file. The default value is 5. The number of threads should be equal to the number of job schedulers that run simultaneously.
Unlike queue processors, a job scheduler needs to decide whether a record needs to be locked. It also must decide whether it needs to commit records that have been updated using Obj-Save. If a job scheduler creates a case or opens a case with a lock and causes it to move to a new assignment or complete its life cycle, it is unnecessary for the job scheduler to issue a commit.
Listeners
Use listeners for email, file, or inbound network requests or messages. In a high availability environment, listeners should be distributed across hosts and Pega Platform servers by using node types to assure redundancy.
File listener uses a file service to import and process files from another system or are created by application users. For example, you can import data that is used to create a work object.
Email listeners identify the listener, the email account name, the name of the mail folder to monitor, the message format of the incoming messages, and the email service rule to which to route messages. Use email listeners to provide necessary information to route incoming email messages to an email service rule (Rule-Service-Email rule type).
JMS listeners provide Pega Platform with the information it needs to route Java Message Service (JMS) messages from a specific topic or queue to a Pega Platform JMS service ( Rule-Service-JMS rule type). A JMS listener or JMS MDB listener data instance specifies which queue or topic contains the messages to be consumed and which JMS service rule(s) will process the messages.
Caution: JMS MDB Listener rules are no longer being actively developed and are being considered for deprecation in upcoming releases. Using JMS MDB Listener rules does not follow Pega development best practices. Consider other implementation options instead.
Service-level agreements
Using service-level agreements (SLAs) is a viable alternative to using an agent in some situations. An SLA escalation activity provides a method for you to invoke agent functionality without creating a new agent. For example, if you need to provide a solution to conditionally add a subcase at a specific time in the future, then adding a parallel step in the main case incorporating an assignment with an SLA and escalation activity can perform this action.
Tip: The standard connector error handler flow Work-.ConnectionProblem leverages an SLA to retry failed connections to external systems.
An SLA must always be initiated in the context of a case. Any delay in an SLA process impacts the timeliness of executing the escalation activity. It should not be used for polling or periodic update situations.
The SLA Assignment Ready setting allows you to control when the assignment is ready to be processed by the SLA agent. For example, you can create an assignment today but configure it to process tomorrow. An operator can still access the assignment if there is direct access to the assignment through a worklist or workbasket.
Note: Pega Platform records the assignment ready value in the queue item when the assignment is created. If the assignment ready value is updated, the assignment must be recreated for the SLA to act on the updated value.
Wait shape
The Wait shape provides a viable solution in place of creating a new agent or using an SLA. The Wait shape can only be applied against a case within a flow step and wait for a single event (timed or case status) before allowing the case to advance. Single-event triggers applied against a case represent the most suitable use case for the Wait shape. The desired case functionality at the designated time or status follows the Wait shape execution.
In the FSG Booking application, a good example of Timer Wait Shape is desirable in a loop-back polling situation where a user may want to have an operation executed immediately within the loop-back. In this example, a user may want to poll for the current weather forecast instead of waiting for the next automated retrieval to occur. As shown, this loop-back can be implemented in parallel to a user task such as flagging weather preparation set up and tear down task completion.
It is overly complex to update a queue processor’s record to fire as soon as possible, then have to wait several seconds to see the result.
Data flow
Data flows are scalable and resilient data pipelines that you can use to ingest, process, and move data from one or more sources to one or more destinations. For example, a simple data flow can move data from a single data set, apply a filter, and save the results in a different data set. More complex data flows can be sourced by other data flows, can apply strategies, text analyzer, event strategies for data processing, and open a case or trigger an activity as the final outcome of the data flow.
Data flows can be run in three different modes:
- Use Batch run of data flow to make simultaneous decisions for large groups of customers.
- Use Real-time run of data flow to process latest data with a stream able data set source.
- Use Single Case data flow run to process for a single interaction case which trigger from DataFlow-Execute method .
Standard agent
Caution: Consider using a job scheduler or queue processor instead of an agent.
Standard agents are generally preferred when you have items queued for processing. Standard agents allow you to focus on configuring the specific operations to perform. When using standard agents, Pega Platform provides built-in capabilities for error handling, queuing and dequeuing, and commits.
By default, standard agents run in the security context of the person who queued the task. This approach can be advantageous in a situation where users with different access groups leverage the same agent. Standard agents are often used in an application with many implementations that stem from a common framework or in default agents provided by Pega Platform. The Access Group setting on an Agents rule only applies to Advanced Agents which are not queued. To always run a standard agent in a given security context, you need to switch the queued Access Group by overriding the System-Default-EstablishContext activity and invoke the setActiveAccessGroup() java method within that activity.
Queues are shared across all nodes. The throughput can be improved by leveraging multiple standard agents on separate nodes to process the items in a queue.
Note: There are several examples of default agents using the standard mode. One example is the agent processing SLAs ServiceLevelEvents in the Pega-ProCom ruleset.
Advanced agent
Use advanced agents when there is no requirement to queue and perform a reoccurring task. Advanced agents can also be used when there is a need for more complex queue processing. When advanced agents perform processing on items that are not queued, the advanced agent must determine the work that is to be performed. For example, if you need to generate statistics every midnight for reporting purposes,. the output of a report definition can determine the list of items to process.
Tip: There are several examples of default agents using the advanced mode, including the agent for automatic column population pxAutomaticColumnPopulation in the Pega-ImportExport.
In situations where an advanced agent uses queuing, all queuing operations must be handled in the agent activity.
Tip: The default agent ProcessServiceQueue in the Pega-IntSvcs ruleset is an example of an advance agent processing queued items.
When running on a multinode configuration, configure agent schedules so that the advanced agents coordinate their efforts. To coordinate agents, select the advanced settings Run this agent on only one node at a time and Delay next run of agent across the cluster by specified time period.
Batch scenarios questions
Question: As part of an underwriting process, the application must generate a risk factor for a loan and insert the risk factor into the Loan case. The risk factor generation is an intensive calculation that requires several minutes to run. The calculation slows down the environment. You would like to have all risk factor calculations run automatically between 10:00 PM and 6:00 AM to avoid the slowdown during daytime working hours. Design a solution to support this.
Answer: Use a delayed dedicated queue processor. Set the DateTime for processing to 10:00 PM. The case will waits for the queue processor to resume the flow for next processing.
It can take advantage of other claims processing queue processors if enabled on other nodes, reducing the time it takes to stop process all of the loan risk assessments.
Question: You need to automate a claim adjudication process in which files containing claims are parsed, verified, adjudicated. Claims which pass those initial steps are automatically created for further processing. A single file containing up to 1,000 claims is received daily before 5:00 PM. Claim verification is simple and takes a few milliseconds. Still, claim adjudication might take up to five minutes.
Answer: In an activity, invoke the Queue-For-Processing method against each claim.
Using the File service activity only to verify claims and then offload the task to the queue processor is preferred because it does not significantly impact the intake process. It can also take advantage of multimode and threading processing if available. Furthermore, the modular design of the tasks would allow for reuse and extensibility if required in the future. However, if you use the same file service activity for claim adjudication, it impacts the time required to process the file. Processing is only available on a single node and there is little control over the time frame while the file service runs. Extensibility and error handling might also be more challenging.
Consideration must be given on time a queue processor requires to complete the task. For example, the time required to process the claims by a queue processor is 5,000 minutes (83.33 hours); this is not suitable for a single queue processor running on a single node to complete the task. A system with the queue processor enabled on multiple nodes with multiple threads could perform the off-hours task. An alternative solution is to split the file into smaller parts, which are then scheduled for different queue processors (assuming there is enough CPU available for each Queue processor to perform its task).
Question: ABC Company is a distributor of discount wines and uses Pega Platform for order tracking. There are up to 100 orders per day, with up to 40 different line items in each order specifying the product and quantity. There are up to 5,000 varieties of wines that continuously change over time as new wines are added to and dropped from the list. ABC Company wants to extend the functionality of the order tracking application to determine recent hot-selling items by recording the top 10 items ordered by volume each day. This information is populated in a table and used to ease historical reporting.
Answer: Use job schedulers, which runs after the close of business each day, and it performs the following tasks:
- Opens all order cases for that day and tabulates the order volume for each item type
- Determines the top 10 items ordered and records these in the historical reporting table
The activity should leverage a report to easily retrieve and sort the number of items ordered in a day. When recording values in the historical table, a commit and error handling step must be included in the activity.
If you are having problems with your training, please review the Pega Academy Support FAQs.
Want to help us improve this content?