PdfConnector component usage and configuration
The PdfConnector component allows you to automate PDF files with or without user interaction. While you cannot create or view a PDF file using the component, the PdfConnector allows an automation to interact with PDF files to complete a task, such as:
- Completing a PDF form by using the data that is retrieved from an application.
- Entering relevant data from a PDF file into an application.
- Extracting text values from a PDF file with Optical Character Recognition (OCR) marks and creating a case for further processing.
- Determining if a signature is present on a PDF file using OCR mark detection.
- Extracting table data and using a loop to create multiple cases for further processing.
- Annotating or adding comments to a PDF file.
Document types
Document types are documents that are identifiable with known elements of a text or by the presence of known form fields. Examples of document types include:
- Expense report
- First Notice of Loss insurance form
- Change of Address form
Each of these documents has a distinct format that can be used to identify them uniquely. During the design phase of the solution development, you interact with a PDF file that directly represents the PDF files with which the automation interacts. You create document identifiers that act similarly to match rules for the document. You also set whitespace thresholds for the document and map the values that you use from the document by drawing boxes around elements in the PDF file.
When a new document is opened at run time, the PdfConnector compares the documents with existing document types. When a document type is a match, the PdfConnector raises a DocumentOpened event. Automations use the values from the document type loaded.
Configuration of a document type
A PDF file can be a PDF form with form fields, a text-based PDF with no form fields, or a file with a combination of both form fields and text elements. At a high level, the workflow for adding a new document type is:
- Set the file location of the document.
- Name the document type.
- Adjust the whitespace thresholds (for text files).
- Add at least one document identifier, such as a text or form field that uniquely identifies the document.
- Select the form fields, text, optical marks, or tables that you wish to extract from the document.
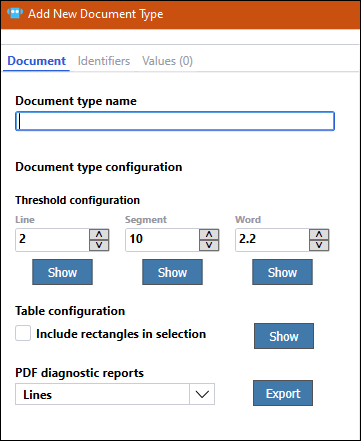
The Add New Document Type wizard has multiple tabs on which document type configuration occurs.
The Document tab allows you to name the document type and adjust how the PdfConnector processes your document with thresholds and table configuration. You can also run diagnostic reports to see how different whitespace thresholds affect how the document is processed.
The Identifiers tab allows you to select the elements of the document to identify the document type uniquely. Identifiers act similarly to match rules for a Document Type. At least one identifier is required, and multiple identifiers may be required to differentiate between forms that have similar structural similarities.
The Values tab allows you to select and customize the data values for the document type. These values are available for automation during run time.
Check your knowledge with the following interaction.
If you are having problems with your training, please review the Pega Academy Support FAQs.
Want to help us improve this content?