
Voice AI models
You can help train the models that Voice AI uses to transcribe customer conversations and identify topics and entities. Voice AI uses different AI models for transcription and for natural language processing (NLP).
- Speech Service AI model – Train custom AI models using customer data to improve accuracy of Voice AI transcription.
- Text Analyzer NLP models – Train models to better suggest cases and knowledge articles as well as to autofill forms.
AI model for the Speech Service
The Speech Service component of the Voice AI architecture transcribes audio from the customer conversation in real time. The Speech Service, as shown in the following diagram, uses an AI model to detect and transcribe the audio content:
Text Analyzer NLP models
The Pega NLP component of the Voice AI architecture analyzes the customer conversation to identify topics and entities, and then pushes suggestions to CSRs in real time in the Interaction Portal. Pega NLP is part of the Pega Server, as shown in the following diagram.
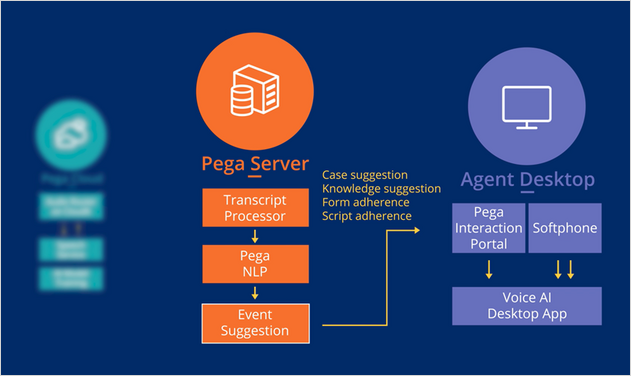
When you create a Voice AI channel, a Text Prediction is generated. The Text Prediction includes models for topic, sentiment, and entity extraction. The following screen shows the models used with a sample Voice AI channel.
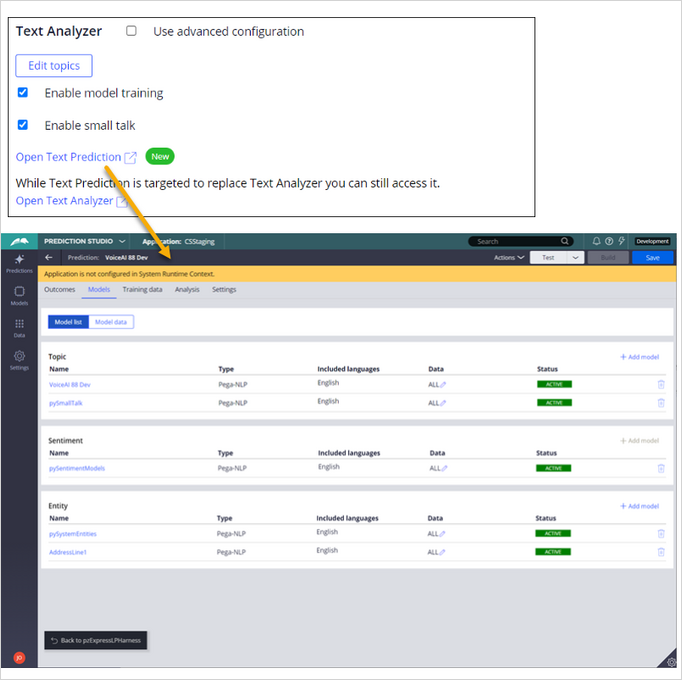
The topic models analyze the customer conversation to suggest the appropriate case type to the CSR.
Sentiment models detect the emotion expressed in a conversation as generally positive or negative.
The entity models detect words in the customer conversation that can be associated with case data, such as a name or address.
You can use the Prediction Studio to modify and train models. In most cases, a data scientist maintains the models.
Training data
You can help train a topic model by adding records to the model. Each training record is a combination of a topic and an associated word or phrase relevant to your organization. You classify each record by associating it with the appropriate topic. For example, the following screen shows a training record from a typical customer conversation.
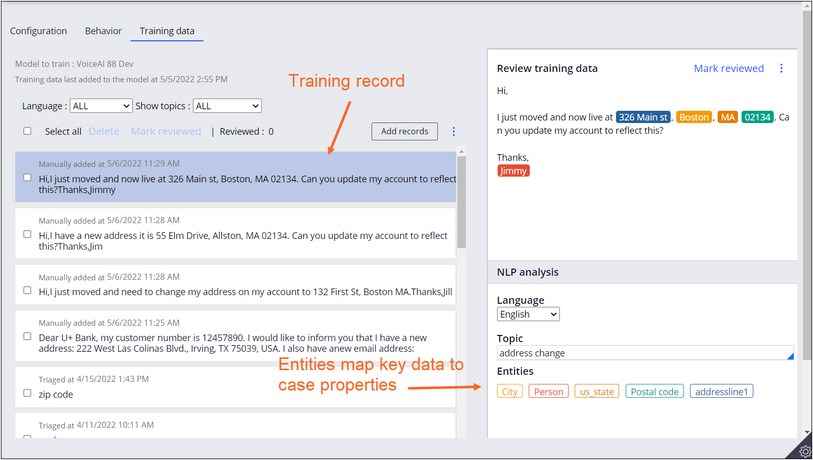
The NLP analysis for the selected record shows the identified entities, such as street address and city. This record is associated with the address change topic
You can review the NLP analysis and mark records as reviewed.
You can monitor a model for accuracy, rebuild a model, and export or import the models across different Pega environments. Each time you rebuild the model, Voice AI calculates a new score, which represents the overall accuracy of the model for all topics.
For more information about configuring and training NLP models, see the Pega Academy mission Pega NLP Essentials.
This Topic is available in the following Module:
If you are having problems with your training, please review the Pega Academy Support FAQs.
Want to help us improve this content?