Using a database index for report performance
Archived
5 Tasks
5 mins
Advanced
English
Scenario
Front Stage wants to investigate the impact of expanding its address search capability to include filtering on street addresses that start with a certain number. They are aware of a source of actual address information that they can use: OpenAddress . Front Stage is concerned that, over time as the Address table grows larger, and with greater use of address search, query performance could impact their ability to efficiently process cases.
The following table provides the credentials you need to complete the exercise.
| Role | Operator ID | Password |
|---|---|---|
| Admin | Admin@Booking | rules |
| pgAdmin4 | pega | pega |
Your assignment:
You will analyze the possible performance impact of expanding the address search capability to include filtering on street addresses. To do this you will first need to insert a large amount of test data into the FSG-Data-Address table, customerdata.fsg_data_address. Then you will test a street filter condition to be used with the Haversine formula. To do this you do not need to modify the HaversineFormula Connect-SQL rule. Instead you will execute the modified query from PostSQL pdAdmin4 tool. In order to analyze the query, you will prefix the query using EXPLAIN (ANALYZE true, COSTS true, FORMAT json). You will first execute the query and note the result. Then, you will add a database index to the street column. Then execute the query again and compare the result from your first run.
Detailed Tasks
1 Detailed steps
Download Address data
Note: Excercise.zip is provided with this exercise. You may need to download the file. Transfer the ZIP file to $/home/architect/Desktop directory. You can also unzip files using the File Manager.
2 Load CSV address data into the PostgreSQL database
Within pgAdmin4, launch the Query Tool. Open SQL file fsg_data_address_import.sql from the Exercise folder and execute.
select count(*) from customerdata.fsg_data_address to verify that all the records loaded successfully.
3 Analyze and improve query performance
Instead of modifying the Haversine formula by adding a filter criterion such as AND street LIKE '1 ROGERS STR%', it is enough to perform a simple query within pgAdmin4 against the address table such as the one shown below.
| EXPLAIN (ANALYZE true, COSTS true, FORMAT json) SELECT pinguid AS pyGUID, reference AS Reference, isfor AS IsFor, street AS Street, city AS City, state AS State, postalcode AS PostalCode, country AS Country, latitude AS Latitude, longitude AS Longitude FROM customerdata.fsg_data_address WHERE street like '1 ROGERS STR%'; |
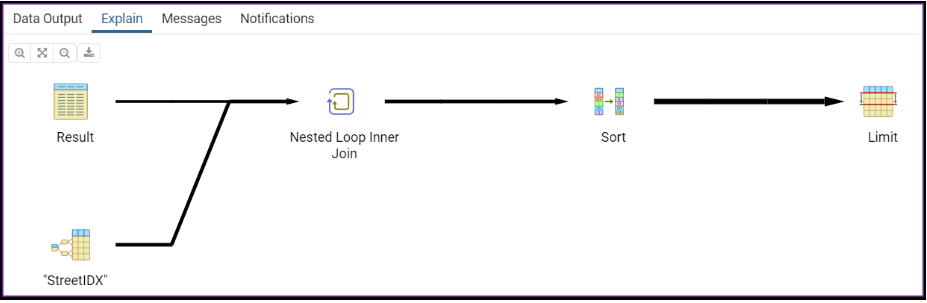
In the “Explain” tab hover over the icon. On the right you should see the statistics for the Sequential Scan that was performed.
Next select Indexes beneath pr_fsg_data_address, right-click, and select Create. Provide an index name such as idx_street or StreetIDX. In the Definition table select btree then add the street column to the index. Choose any Operator class such as text_pattern_ops.
Execute the query again. This time you should see significantly faster performance due to an Index Scan being used.
If you want, do the same for a modified version of the Haversine formula. The Explain graphic will be different.
|
EXPLAIN (ANALYZE true, COSTS true, FORMAT json)
Note: Attempting to index the latitude and longitude columns will not improve performance since these are numeric. pgAdmin4 does not support the definition of indexes for numeric columns, Forcing an index on a numeric column using DDL syntax, for example, CREATE INDEX idx_lat ON customerdata.fsg_data_address(latitude), will not work; the index will be ignored.
|
4 Verify your work
Indexed columns should result in significantly improved performance readings.