Best practices for data models
Years ago, when Pega Platform™ was known as PegaRULES Process Commander (PRPC), configuring a data class as abstract, as opposed to concrete, was important. The terms “abstract” and “concrete" are borrowed from the Java programing language. An abstract class is one that can only be inherited, not constructed. An example within the Booking sample application is FSG-Data-Location. In Java, if you attempted to create an abstract class using the new() operator you would get a compilation error, but PRPC would not prevent you from directly creating an FSG-Data-Location page on the clipboard using a data transform or activity.
Today, the main distinction within Pega Platform between abstract and concrete data classes is that an abstract data class does not define keys. A data class that does not define keys cannot be stored in a database table: no keys, no database storage. Every database table requires a primary key.
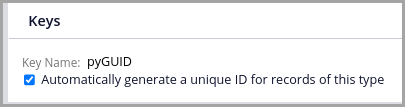
Beginning with version 7.3, Pega Platform added the capability to the Rule-Obj-Class rule that tells the system to generate a unique ID. If no key is specified, Pega Platform will use .pyGUID as the property that contains the generated key. It is virtually impossible for a .pyGUID value to be duplicated. This has the advantage that application code can control an instance’s primary key, instead of being dependent on the database to prevent key duplication. This then allows application code to define a Save Plan capable of persisting multiple data instances at once, where every instance references an instance of a different class.
The following figure shows the section of a Rule-Obj-Class rule form where .pyGUID can be configured as the primary key prior to a local source being generated. When a data type is defined in App Studio, this box will have been checked.
The CustomerData schema eliminated the need for a database table to contain Pega-specific columns such as .pzPvStream and .pzInsKey. If you store a data class in the CustomerData schema you must avoid code that expects to reference instances of that class by pzInsKey. Instead, you must reference the instance by its keys, for example, .pyGUID. A data instance does not need to reference a case using the case’s .pzInsKey value, but can instead reference a case by its key, .pyID. Note that Pega does not allow .pzInsKey to be defined as a Property-type Relevant Record.
Concrete data classes
The definition of concrete is very clear: concrete refers to something that you persist outside of a case, something that a case can reference, and so on. The term “referential data” is applied to the type of data that, in general, either has no references or very few references to other data. You can think of referential data as long-lived data.
Referential data embedded within a case’s BLOB should be avoided unless there is a requirement to do so. One reason to copy data is because its values are transient, meaning that they only last for a short time. Take, for example, the value for a product’s price. Over time, the price can change. When copying the price data, it then makes sense to also copy the reason why the price data was copied. For example, the price record’s AsOfDate could be used to find the historical price in the future, using a database lookup.
Copying a computed and used, historically, price is beneficial for performance reasons because the system does not have to re-perform the same calculations used to compute its value. This approach is comparable to having an invoice with numerous line items.
When there are no calculations for the system to perform, it makes sense to do a Lookup (SOR Pattern) or JOIN from the case to the referential data, instead of embedding it as a Snapshot Pattern in the case’s BLOB.
It should be possible to package and deploy referential concrete class instances without any prerequisites or limitations.
For example, consider the FSG-Data-Hotel and FSG-Data-Venue instances, which extend FSG-Data-Location. Imagine that rather than referencing an FSG-Data-Contact instance stored in the CustomerData schema, FSG-Data-Location had embedded a “Contact” page of class Data-Party. FSG-Data-Location would then be forced to be persisted in the PegaData schema. Regardless, because that Contact page is still owned by (aggregated by) Hotel or Venue instances, they are transportable. FSG-Data-Location also owns (aggregates) FSG-Data-Address instances; FSG-Data-Address instances only reference an FSG-Data-Location instance.Therefore, FSG-Data-Address instances can be packaged with the FSG-Data-Location instances that they reference.
It does not make sense for a referential data class to have an embedded PageList (Field Group List) where each page in the list references an historical data instance. The list would grow indefinitely over time which would be problematic. This is like the Open/Closed principle but applied to persistence instead of inheritance. A true concrete instance can choose to remain “closed” to modification. In contrast, an instance that contains an embedded PageList (Field Group List) that can grow indefinitely requires its BLOB to be continually modified.
Abstract data classes
A good example of an abstract class is FSG-Data-Hotel-RoomsRequest, which is shared by the Hotel and HotelProxy application by way of a mutually used Component. FSG-Data-Hotel is a concrete class defined at the Enterprise level. When using the Data Type wizard to define a new data type, it is possible to select one that already exists, including a concrete class. The Data Type wizard appends the name that you enter, for example, RoomsRequest to the name of the existing class, for example, FSG-Data-Hotel using a dash as a separator to create a pattern-inheriting class.
Although possible, the embedded FSG-Data-Hotel-RoomsRequest page is never persisted, instead it is used purely for integration between the Hotel and HotelProxy applications.
Another example is when a historical data type has several scalar properties. Suppose multiple case types can be defined that strictly involve that data type. Also suppose those cases, and that historical data type, are virtually synonymous.
Data classes provide for reuse of rules such as views, data transforms, and so on. The data class minimizes the number of case-level properties that are created.
Reports that include properties within the embedded page’s data class are slightly more complex. Properties within the embedded page need to be exposed using Optimize for reporting. The exposed column is shown in the Class rule’s External Mapping tab.
Enterprise-level vs application-level data classes
Every data class that is central to how an organization does business should be defined in the Enterprise layer. If a data class is central to an organization, any related applications that are developed in the future should use the same class. It does not make sense for two Pega applications within the same organization to be forced to share information by way of integration and data transforms. Instead, the data class should be the same. This approach is no different than expecting Pega data classes such as Data-Party to be used by every application.
If an application has additional properties that it would like to add to an enterprise-level data class that would not be applicable to other applications, that application is free to directly inherit the enterprise-level data class and add those properties. According to the Open/Closed principle, anything that works well at the enterprise level should work equally as well at the application level, from the enterprise application’s point of view. The enterprise application does not care what is specifically done at the application level, it only cares that functionality “X” was correctly and successfully run.
It is also fine for an application to define data classes that are specific to that application. This should be done when no other application would have a reason to use the same data class. Data classes that meet this definition would be rare, and not the norm.
Naming data classes
It is common for a case to capture data using a data type synonymous with the case type's class. In general a case name should be an action + noun, or noun + action. This is because it is possible for the same noun, such as “Event”, to be processed by multiple case types. BookEvent and BillEvent are two case types that operate on Event data.
Because a data class represents both a noun and an object, it is not necessary to append the word "details" to the noun because that is what the object does –it encapsulates details or information about itself. So you should avoid redundancy in your naming conventions. The word "details" does not add value. Just the opposite, that word calls into question whether Event and EventDetails are two different objects..
It is considered poor practice to repeat a property’s class name within its own name. For example, you would not name an FSG-Data-Event property EventStartDate. You would instead name the property StartDate.
The BookEvent case does not need a Field Group property named EventDetails when Event is sufficient. The class of the Event Field Group should be FSG-Data-Event, not FSG-Data-EventDetails.
Avoiding data redundancy
Data integrity is about maintaining a ‘single source of truth,’ meaning that you do not store the same data in two locations. This is the reasoning behind database normalization techniques. The first and foremost of these techniques is “…to free the collection of relations from undesirable insertion, update and deletion dependencies” (Edgar F. Codd, 1970). Consider what would happen if the same data or a derivative of that data, for example, the Promoter Score Category, is stored in multiple places and the original data is changed. The difficulty and complexity of maintenance tasks increases dramatically if an application is expected to keep track of, and update, every location in which a value is stored, whenever the value changes. For example, imagine a Rule-Declare-Trigger that has to deal with multiple locked instances simultaneously. This would cause lots of problems.
Check your knowledge with the following interaction.
If you are having problems with your training, please review the Pega Academy Support FAQs.
Want to help us improve this content?