Migrating sampled data with a data migration pipeline
The data migration pipeline facilitates the process of moving sampled production data into the business operations environment (BOE) automatically. It provides you with the means to simulate what-if scenarios on the sample production data without affecting the production environment.
Video
Transcript
This video shows you how to configure a data migration pipeline to migrate sampled production data from the production environment to the business operations environment.
U+ Bank, a retail bank, plans to configure Pega Deployment Manager to set up a data migration pipeline and migrate 20% of its customer base from the production environment to the BOE for the business users to simulate what-if scenarios.
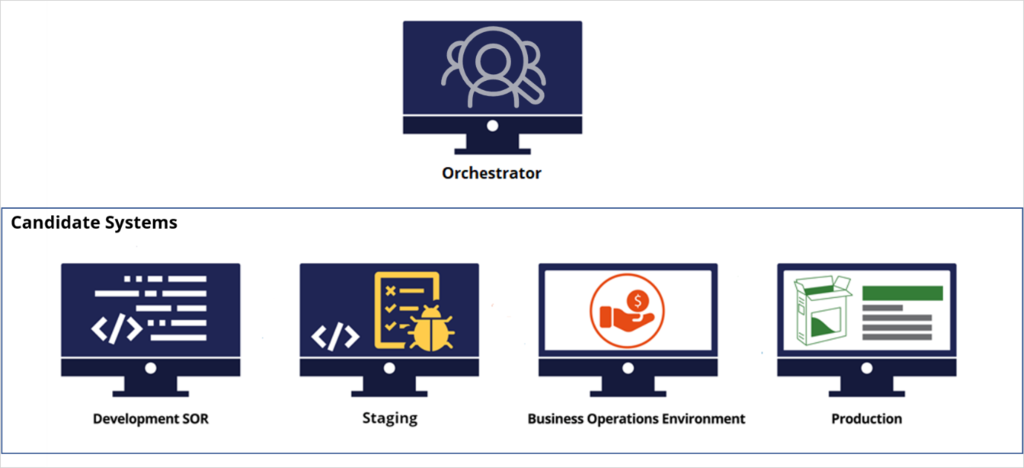
A typical decision management project involves five environments:
- An orchestrator to manage and automate the deployment process of artifacts to the candidate environments
- A development (system of record) environment to develop enterprise capabilities
- A staging environment to test the changes and analyze their technical impact
- A business operations environment (BOE) to make business changes
- A production system to serve customers with the latest artifacts
To implement this requirement, first ensure that the BOE and the production environment communicates with the orchestrator. Next, in the orchestrator, configure a data migration pipeline to define the migration process of the sampled production data. Once the Release Manager configures the pipeline, customer interactions in the production environment are sampled and migrated to BOE through a data migration pipeline.
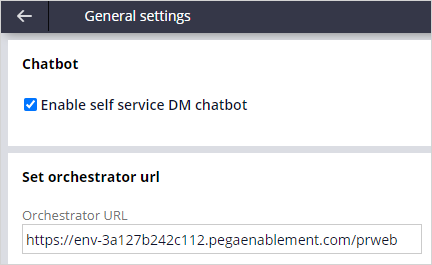
In the BOE and the production environment, update the PegaDevOpsShared dynamic system setting (DSS) to point to the orchestrator system URL. Updating the DSS links the BOE and production systems to the orchestrator system.
Then, configure a data migration pipeline in the Deployment Manager portal in the orchestrator. The data migration pipeline allows you to move data from one environment to another so that you can run simulations on a preselected sample set of customers. You can make millions of decisions simultaneously and simulate the outcome of your decision management framework.
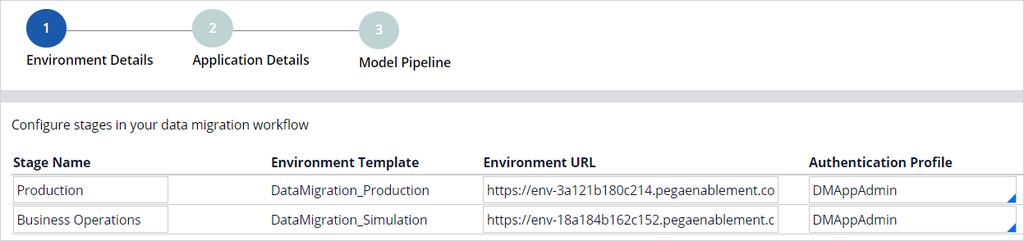
Deployment Manager comes with out-of-the-box pipeline templates that help you structure pipelines based on their purpose. For this requirement, use the Data Migration Pipeline template. Begin by providing the URL of the production environment.
Then, select the Authentication profile that communicates with the candidate environments. An authentication profile is automatically created during the installation of Deployment Manager. The orchestrator uses this authentication profile to communicate with candidate systems to run tasks in the pipeline. Use this authentication profile in all the candidate systems with the same operator ID.
Now, provide the URL of the BOE, and then select the authentication profile.
Select the name and version of the enterprise application. Then, select the access group for which you want to run the pipeline tasks. Ensure that this access group is present in all environments.
Now, enter a unique name for the pipeline, Data Migration to create a model pipeline.

The pipeline model is a case type that defines various predefined tasks that are necessary to accomplish a successful data migration.
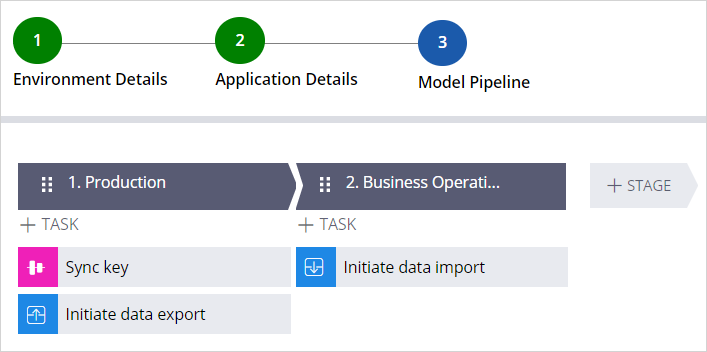
Run diagnostics to check if the orchestrator can communicate with the BOE and production systems and application details on the pipeline are defined correctly. On successful check, the pipeline is ready to migrate the sampled data from the production environment to the BOE.
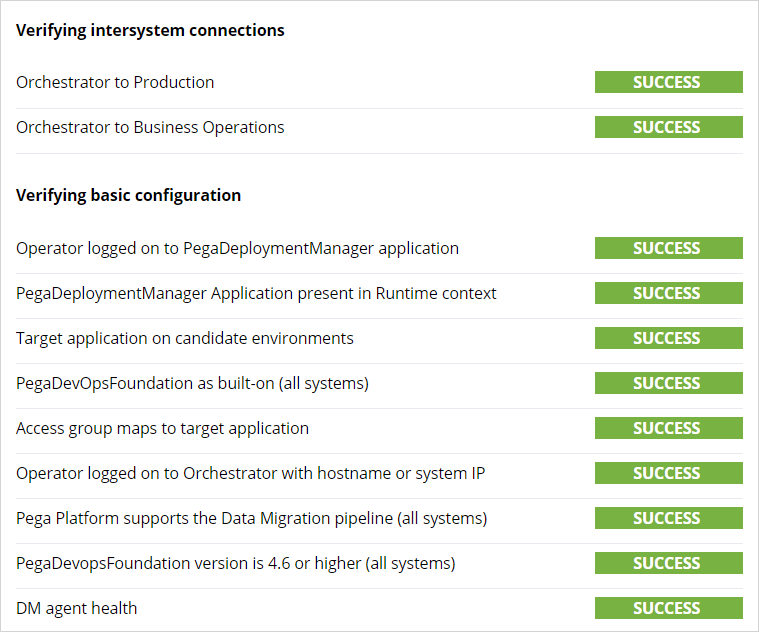
Access the U+ Bank website from the production environment. Log in as different customers to record varied interactions. When you prepare the system for data migration, you configure the data migrations settings that sample the customer interactions.
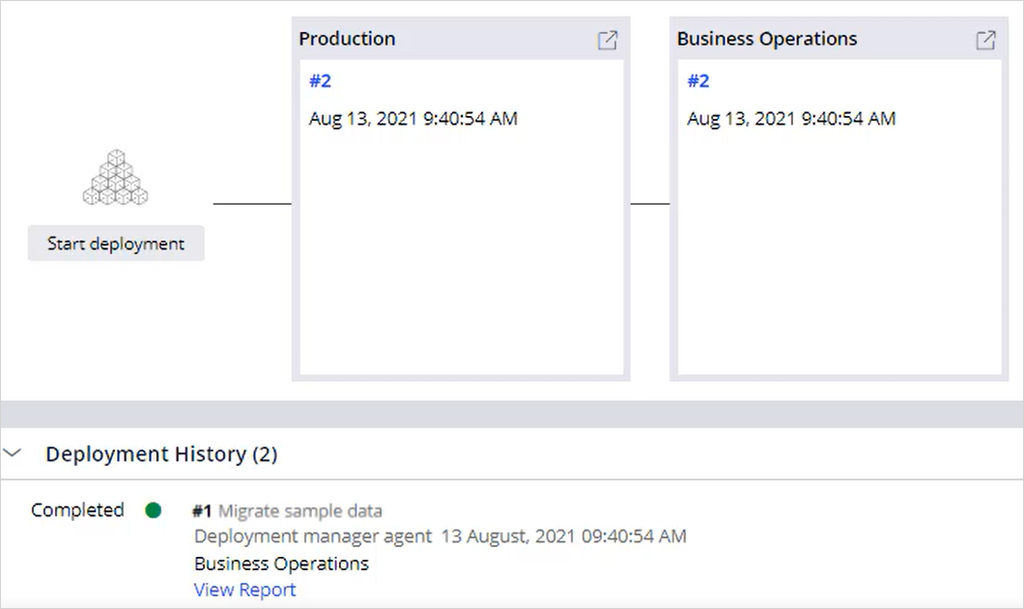
You can initiate the data migration now that you have successfully created the pipeline and recorded some interactions.
While the migration is in the first stage, access the production environment to view the case that the system creates to export production data. Monitor the case to see the various tasks that are performed. The case shows the number of processed inbound samples, adaptive model data, and reports.
Notice that all adaptive models from the production system are migrated to the BOE. This migration ensures that the simulations that run in the BOE are accurate in gauging expected outcomes. On completion of the case, navigate to the orchestrator to see that the deployment advances to the second stage.
Navigate to the BOE to view the data import case. Monitor the case to see the various tasks that the performed. On completion of the case, navigate to the orchestrator to see that the deployment is complete.
In the BOE, search for and open one of the sampled data sets to view the structure and content of the sampled data. You can also view the Recent Interactions in the Interaction history.
When the system creates new interaction records, the records accumulate in the production environment. After reinitiating the data migration pipeline, the system samples the latest production data, which overwrites the sampled data set in the BOE. In this way, the BOE contains a sample of the latest production data.
You can also schedule a data migration pipeline to run during a specified period by creating and running a job scheduler.
You have reached the end of this video. What did it show you?
- How to configure a data migration pipeline and establish communication between environments.
- How to migrate sampled production data with a data migration pipeline.
This Topic is available in the following Module:
If you are having problems with your training, please review the Pega Academy Support FAQs.
Want to help us improve this content?