
Training a topic model to improve email routing
Introduction
U+ Bank uses Pega Customer Service™ to route incoming emails to the appropriate department based on the topic of the email. For several use cases (for example, an address change), emails are routed based on keywords that are detected in the message. To improve the email routing, learn how to train the text prediction with a data set that contains classified messages.
Video
Transcript
This demo shows you how to train a text prediction to improve email routing.
U+ Bank uses machine learning to route inbound messages in the email channel to the appropriate department based on the topic of the email.
A text prediction that aims to detect the topic of the message drives the routing.
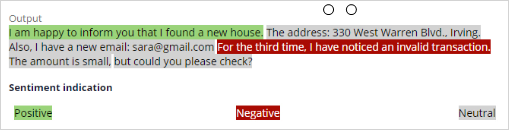
For example, when Sara writes an email to inform U+ Bank that she has moved to a new house, the text prediction detects an address change as the topic.
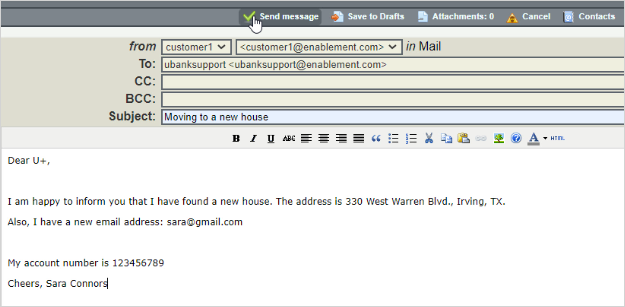
The Account maintenance department receives all emails where an address change is detected as the topic of the message.
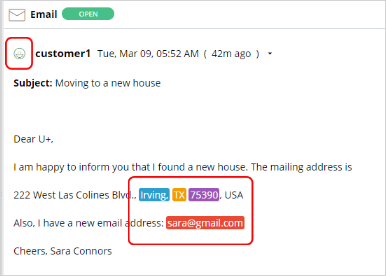
The text prediction also detects entities such as a ZIP Code and an email address and the overall sentiment of the message.
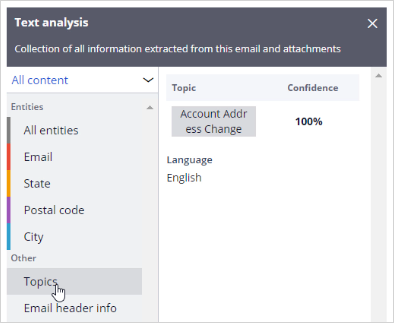
Notice that the topic Account Address Change is detected with 100% confidence.
The intelligent routing is set up in the email channel, in App Studio.
An email is routed to the work queue of the Account maintenance department when the detected topic is an address change.
Complaints are routed to the Transaction Disputes department.
If the address change and complaint topics are not detected, the email is routed to a default work queue.
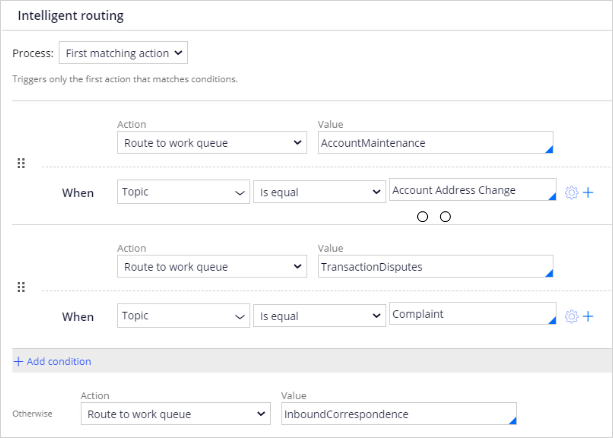
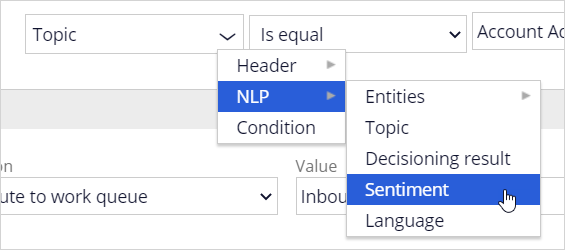
Note that in the When condition of the email routing, you use the outcome of the text prediction.
Optionally, you can also use the sentiment of the email in the routing conditions.
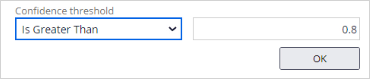
You can set a threshold for the confidence with which a topic must be detected to trigger routing.
Every channel is associated with a text prediction.
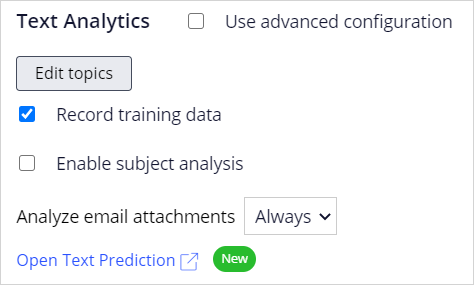
A text prediction is driven by predictive models that detect topics, entities, and sentiments.
Many entity extraction models, and a sentiment model, are available out of the box.
For topic detection, Prediction Studio supports keyword models as well as machine learning models based primarily on training data.
A keyword model uses Should words, Must words, And words, and Not words.
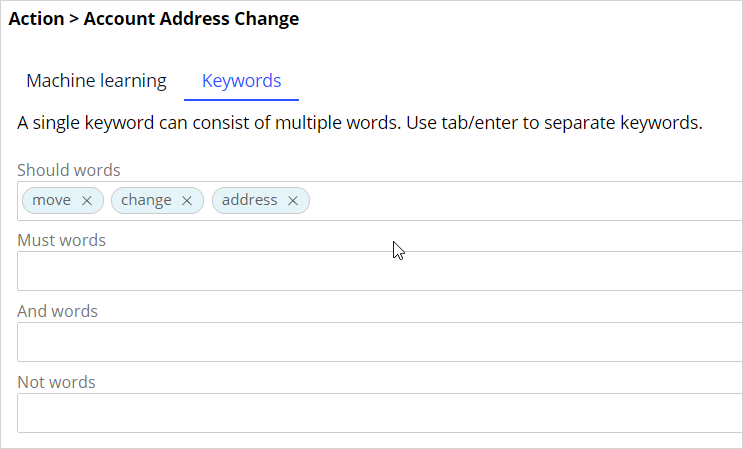
If any of the Should words appear in a piece of text, topic detection assigns that text to the corresponding topic. To achieve accurate results, create an exhaustive list of Should words.
Only if all Must words appear in a piece of text, will the topic detection assign that text to the corresponding topic.
Use And words to distinguish between similar topics while using identical Must words.
If a Not word appears in a piece of text, the text is not assigned to the corresponding topic.
You can test the output of a prediction on a sample message.
Two topics are correctly detected: an address change and a complaint.
Notice that the confidence score for both topics is 1. The keyword model performs a Boolean match based on the presence or absence of words and detects the topic with absolute certainty.
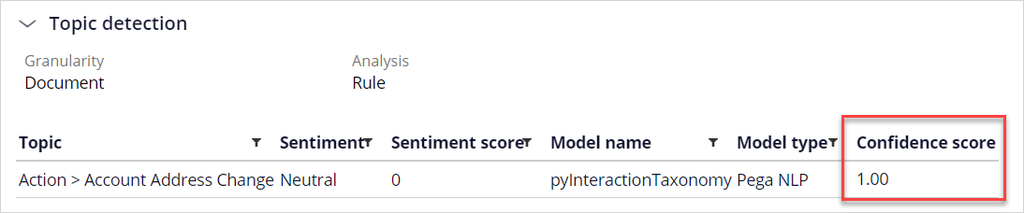
It is highly recommended to use a machine learning model for topic detection. It determines the confidence score based on evidence.
A machine learning model is based on training data that consists of categorized texts.
You can get training data from two sources. The first is training data accumulated through the application that is running in production.
When a customer service representative corrects the topic of an incoming email, this change is added to the training data.
After the messages are reviewed and approved, they are used to rebuild the topic model.
Also, you can choose to import data, provided you have accumulated data in the past.
The file must contain the message and the associated topic.
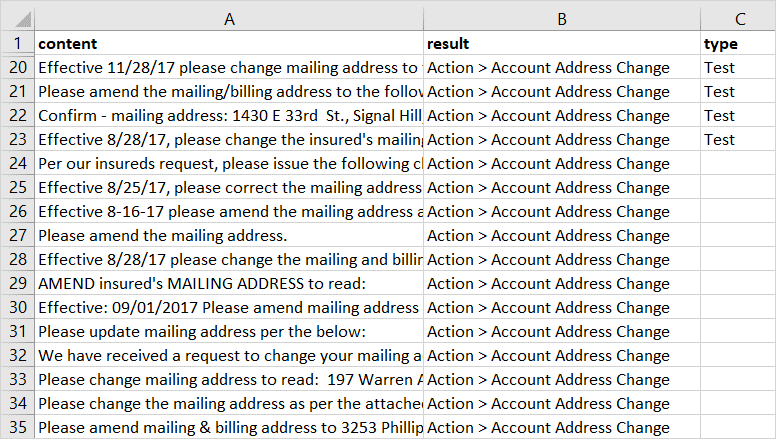
Notice that training data for the address change and the complaint topics are in the pending state.
You can now rebuild the models.
You can select individual models or rebuild all models across model types and languages.
While training is in progress, you have the option to cancel.
When the process completes, you can view the latest model report on the Models tab.
The report contains the validation data, the confusion matrix, and the score sheet.
The topic detection now uses machine learning models based on the training data and the keywords provided for the address change and complaint topics.
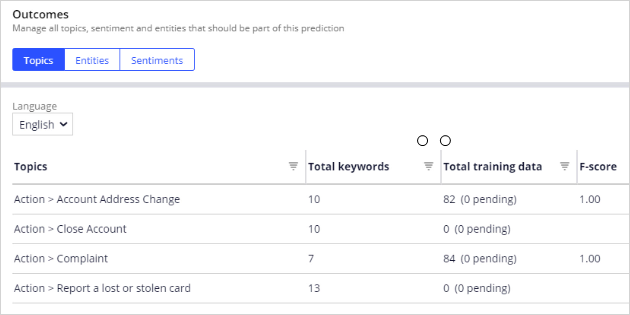
The Should words and Must words act as positive features for matching text to a topic, while the Not words act as negative features.
But the training and testing data have the greatest impact on your machine learning model, while keywords have a smaller impact.
Once the models are rebuilt, you can test the prediction.
Notice that the topics are detected with a confidence score below one.
In this case, the topic message is recognized as a complaint with high confidence. The address change topic is detected, but with a lower confidence score.
When multiple topics are detected in a message, comparison of the confidence scores allows selection of the one with the highest priority.

The other outcomes of the text prediction are the entities detected, such as an email address and the sentiment of the message.
You have reached the end of this demo. What did it show you?
- How Pega Customer Service routes incoming emails to the appropriate department based on the topic of the email
- How text predictions work to predict the topic and sentiment of a message and detect entities
- How to train a topic model and use machine learning to identify the topic correctly
If you are having problems with your training, please review the Pega Academy Support FAQs.
Want to help us improve this content?