キュープロセッサーとジョブスケジューラー
Pega Platform™は、バックグラウンド処理のためのオプションをいくつかサポートしています。 キュープロセッサー、ジョブスケジューラー、標準エージェント、高度エージェント、サービスレベルアグリーメント(SLA)、Waitシェープ、およびリスナーを使用して、アプリケーションのバックグラウンド処理を設計することができます。
補足: スケーラビリティ、使いやすさ、およびバックグラウンド処理の高速化のためには、エージェントの代わりにジョブスケジューラーやキュープロセッサールールを使用してください。
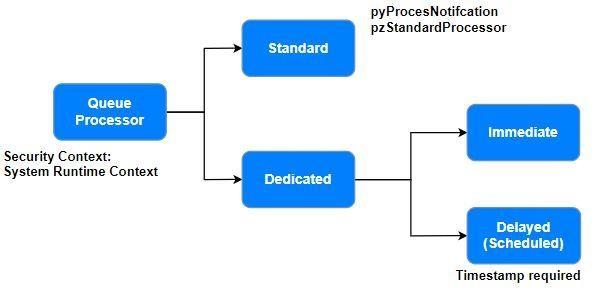
キュープロセッサー
キュープロセッサールールは、キュー管理とメッセージの非同期処理のために設定された内部バックグラウンドプロセスです。 シンプルなキュー管理や低いスループットのシナリオには標準のキュープロセッサールールを使用し、よりスケールの大きいスループットやメッセージのカスタマイズまたは遅延処理には専用のキュープロセッサールールを使用します。
Pega Platformは、Queue-For-Processingメソッドの「Type of queue」セクションでRun in backgroundシェープのオプションを選択すると、メッセージに内部でpzStandardProcessor がトリガーされる、多くのデフォルトの標準的なキュープロセッサーを提供します。 カスタムアクティビティは必ず通過してください。 このルールの可用性は、変更を制限するためにFinal に設定されています。 このキュープロセッサーは即時処理であり、遅延処理が必要なシナリオでは使用できません。
プロセッサールールにより、バックグラウンドで動作する具体的な動作の設定に集中することができます。 Pega Platformは、エラー処理、キューイング、デキューイングを行う機能を内蔵しており、キューイングプロセッサーを使用する場合は、条件付きでコミットすることができます。キュープロセッサーは、共通のフレームワークから作成されるアプリケーションや、Pega Platform自体で使用されるアプリケーションでよく使用されます。
すべてのキュープロセッサーは、System Runtime Context で指定されたコンテキストに対してルール解決を行います。アクティビティでQueue-For-Processingメソッドを設定する場合、またはステージでRun in Backgroundステップを設定する場合、代替のアクセスグループを指定することが可能です。 また、キュープロセッサーが実行するアクティビティによって、Access Groupを変更することも可能です。 例として、pzInitiateTestSuiteRun キュープロセッサーが実行するRule-Test-SuitepzInitiateTestSuiteRunアクティビティがあります。
シンプルなキュー管理には標準的なキュープロセッサーを、カスタマイズされた遅延メッセージ処理には専用のキュープロセッサーを使用します。キュープロセッサーを遅延させる場合、Queue-For-ProcessingメソッドまたはRun in Backgroundスマートシェープで呼び出しながら、日付と時間を定義します。
キューはマルチスレッドで、すべてのノードで共有されます。 つまり、各キュープロセッサーは20のパーティションにまたがってメッセージを処理できるため、キュープロセッサールールは最大で20のスレッドを同時にサポートし、競合も発生しません。 また、複数のキュープロセッサーを活用することで、各アイテムを別々の場所で処理し、スループットを向上させることができます。
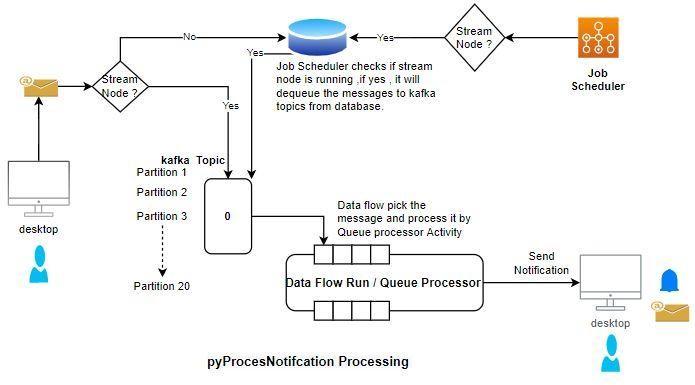
例えば、通知を送る場合を考えてみましょう。 その場合、以下の画像のようなpyProcessNotifcation キュープロセッサーが使用されます。
パフォーマンスには、メッセージの処理時間と、メッセージのスループットの2つの側面があります。 これらは、次のような対処をすることで改善できます。
- アクティビティを最適化し、メッセージの処理時間を短縮します。 メッセージの処理時間は、処理活動の作業量に左右されます。
- 以下の方法でメッセージのスループットが増加させます。
- 処理ノード数の増加によるスケールアウト。 この設定は、オンプレミスユーザーのみに適用されます。 Pega Cloud® Services の場合は、より大きなサンドボックスが必要です。
- ノードあたりのスレッド数を増やすことで、クラスターあたり最大20スレッドまでスケールアップが可能になります。
キュープロセッサーが作成されると同時に、このキュープロセッサーに対応するトピックがKafkaサーバーに作成されます。 server.propertiesファイルに記載されているパーティション数に基づいて、tomcat\Kafka-data folderに同じ数のフォルダが作成されます。
Kafkaサーバーにメッセージをキューイングするためには、少なくとも1つのストリームノードが必要です。 クラスタ内にストリームノードを定義しない場合、アイテムはデータベースに取り込まれ、ストリームノードが利用可能になった時点でこれらのアイテムが処理されます。
デフォルトキュープロセッサー
Pega Platformは、3つのデフォルトキュープロセッサーを提供します。
pyProcessNotification
pyProcessNotificationキュープロセッサーは、顧客に通知を送信し、受信者、メッセージ、またはチャネルのリストを計算するpxNotify アクティビティを実行します。 メール、ガジェット通知、プッシュ通知などのチャネルが考えられます。
pzStandardProcessor
以下の場合は、標準的な非同期処理にpzStandardProcessor キュープロセッサーを使用することができます。
- 処理に高いスループットは要求されないか、処理リソースが多少遅延してもよい場合。
- デフォルトと標準的なキューの動作が許容される場合。
このキュープロセッサーは、各ステータス変更を外部システムに送信するなどのタスクに使用することができます。 バックグランドでの一括処理を実行するのに使用できます。 キュープロセッサーがキュー内のアイテムをすべて解決すると、成功した数と失敗した数が通知されます。
pyFTSIncrementalIndexer
pyFTSIncrementalIndexer キュープロセッサーはバックグランドでインクリメンタルインデックス処理を行います。 このキュープロセッサーは、ルール、データ、ワークオブジェクトを簡単に作成または変更できるように検索サブシステムにポストし、検索データを最新の状態に保ち、データベースの内容をより正確に反映させることができます。
ジョブスケジューラー
繰り返し発生するタスクをキューに入れる必要がない場合は、ジョブスケジューラールールを使用します。 キュープロセッサーとは異なり、ジョブスケジューラーはレコードを処理する前に、どのレコードを処理するか決定し、各レコードのステップページコンテキストを確立する必要があります。 例えば、報告書作成のために毎日深夜0時に統計情報を作成する必要があるとします。 その場合、レポートディフィニションの出力により、処理する項目のリストを決定することができる。 ジョブスケジューラーは、リストの各項目を操作する必要があります。
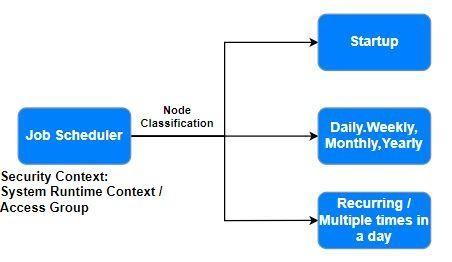
アクティビティに特定のコンテキストが必要な場合、Specify access groupを選択してアクセスグループを提供します。
アクティビティにSystemRuntimeContextが必要な場合(例えば、ジョブスケジューラーとアクティビティ解決に同じコンテキストを使用する)、 Use System Runtime Contextを選択します。
ジョブスケジューラーは、クラスタ内の1つまたは複数のノード、あるいは特定のノードで実行することができます。複数のジョブスケジューラーを同時に実行するには、prconfig.xmlファイルを変更して、ジョブスケジューラースレッドプールのスレッド数を設定する必要があります。 デフォルト値は5です。 スレッドの数は、同時に実行されるジョブスケジューラーの数と同じである必要があります。
キュープロセッサーとは異なり、ジョブスケジューラーはレコードをロックするかどうかを決定する必要があります。 また、Obj-Saveで更新されたレコードをコミットするかどうかを決定する必要があります。 ジョブスケジューラーがロック付きのケースを作成または開き、新しいアサインメントに移動するか、ライフサイクルを完了させる場合、ジョブスケジューラーはコミットを発行する必要はありません。
デフォルトジョブスケジューラー
Pega Platformは、アプリケーションに便利なデフォルトのジョブプロセッサーを提供します。
ノードクリーナー
ノードクリーナーは、期限切れのロックや古いモジュールバージョンレポートをクリーンアップします。
デフォルトでは、ノードクリーナージョブスケジューラー(pyNodeCleaner)は、Code-pzNodeCleanerアクティビティをクラスターのすべてのノードで実行します。
クラスターとデータベースクリーナー
デフォルトでは、クラスターとデータベースのジョブスケジューラー(pyClusterAndDBCleaner)は、Code-.pzClusterAndDBCleaner アクティビティをハウスキーピングタスクのために24時間に1回、クラスターのひとつのノードのみで実行します。 このジョブは、次のような項目をパージします。
- ログテーブルの古いレコード
- 48時間のアイドルリクエスター
- 期限切れリクエストのパッシブ化データ(クリップボードのクリーンアップ)
- 期限切れロック
- 90日以上経過したクラスターステートデータ
ノードとクラスターのステートを保持
pyPersistNodeState は、ノード起動時にノードステートを保存します。
クラスターステートデータは、 pyPersistClusterStateジョブスケジューラーによって1日1回保存されます。
pzClusterAndDBCleaner ジョブスケジューラーは、90日以上経過したクラスターステートデータをパージします。
標準エージェント
注: エージェントの代わりに、ジョブスケジューラーやキュープロセッサーの使用を検討してみましょう。
処理待ちのアイテムがある場合は、標準エージェントを使用することをお勧めします。 標準エージェントは、実行する特定の操作の設定に集中することができます。 Pega Platformは、標準エージェントを使用する場合、エラー処理、キューイングとデキューイング、コミットに関する機能を内蔵しています。
デフォルトでは、標準エージェントは、タスクをキューに入れた人のセキュリティコンテキストで実行されます。 この方法は、異なるアクセスグループのユーザーが同じエージェントを利用するような状況で有利になります。 標準エージェントは、Pega Platformが提供する共通のフレームワークやデフォルトエージェントを使用した多くの実装を持つアプリケーションでよく使用されます。 エージェントへのアクセスグループの設定は、キューに入らない高度エージェントにのみ適用されます。 与えられたセキュリティコンテキストで常に標準エージェントを実行するには、System-Default-EstablishContextアクティビティをオーバーライドして、そのアクティビティ内でsetActiveAccessGroup()javaメソッドを呼び出して、キューに入ったアクセスグループを切り替える必要があります。
キューは全ノードで共有されます。 複数の標準エージェントを使用することで、複数のアイテムを同時に処理することができ、スループットを向上させることができます。
ヒント: 標準モードでは、デフォルトエージェントの例がいくつかあります。 一例として、Pega-ProComルールセットにおけるSLAs ServiceLevelEventsを処理するエージェントが挙げられます。
高度エージェント
キューに入れる必要がなく、繰り返し行われるタスクの場合は、高度エージェントを使用します。 高度エージェントは、より複雑なキュー処理を必要とする場合にも使用することができます。 高度エージェントが、キューに入っていないアイテムの処理を実行する場合、高度エージェントは実行する作業を決定する必要があります。 例えば、報告書作成のために毎日深夜0時に統計データを作成する必要がある場合、出力されたレポートディフィニションの出力によって処理する項目のリストを決定することができます。
ヒント: Pega-ImportExportの自動列生成用エージェント pxAutomaticColumnPopulationなど、アドバンスドモードを使用したデフォルトエージェントのいくつかの例があります。
高度エージェントがキューイングを使用する場合、すべてのキューイング動作はエージェントのアクティビティ内で行われます。
ヒント: Pega-IntSvcsルールセットのデフォルトエージェントProcessServiceQueue は、キューイングされたアイテムを処理する高度エージェントの一例です。
マルチノード設定を実行する場合、高度エージェントが連携して作業できるように、エージェントを設定します。 エージェントを連携させるには、 Run this agent on only one node (at a time) とDelay next run of agent across the cluster by specified time periodの高度な設定を選択します。
デフォルトエージェント
Pega Platformがインストールされると、多くのデフォルトエージェントがシステムで動作するように設定されます(コンピューターオペレーティングシステムで動作するように設定されるサービスと同じです)。 以下のようなデフォルトのエージェントが存在するため、本番システムのエージェント設定を見直し、チューニングします。
- レガシー機能または、あまり使用されない機能を実装するため、ほとんどのアプリケーションでは必要ないエージェント。
- 本番環境では実行してはいけないエージェント。
- デフォルトで不適切なタイミングで実行されるエージェント。
- 必要以上に頻繁に、または不十分な頻度で実行されるエージェント。
- デフォルトではすべてのノードで実行されるが、1つのノードのみで実行されるべきエージェント。
例えば、デフォルトでは、システム内にPega-DecisionEngineを実行するエージェントが複数設定されています。 アプリケーションにデシジョンが適用されない場合は、これらのエージェントを無効にしてください。 Pega-AutoTestエージェントなどは、開発環境やQA環境のみで有効にしてください。 一部のエージェントは、マルチノード構成で単一ノード上で動作するように設計されているものもあります。
エージェントとその構成設定の詳細については、「Agents and agent schedules」を参照してください。 これらのエージェントはロックされたルールセットになっているため、変更することはできません。 これらのエージェントの設定を変更するには、エージェントルールから生成されるエージェントスケジュールを更新します。
トレーニングを実施中に問題が発生した場合は、Pega Academy Support FAQsをご確認ください。