Best practices for data models
Data model best practices
Declaring a data class as abstract as opposed to concrete was more significant in the past. The names for classes declared that abstract classes must end in a hyphen. Now that requirement has been dropped.
The terms "abstract" and "concrete" were borrowed from the Java language. An abstract class is one that can only be inherited, not constructed. In Java, if you attempt to create an abstract class using the new() operator, you get a compilation error.
An example of an abstract class, as Pega uses the term, is the Booking application's FSG-Data-Location class. In Pega, you are free to create an FSG-Data-Location page on the clipboard by using Pega-New in an Activity or, with a data transform, simply setting a property on an FSG-Data-Location step page.
Today, the main distinction within Pega between "abstract" and "concrete" is that "abstract" means that the data class does not define keys. A data class that does not define keys cannot be stored in the database table.
The newer CustomerData schema removed the requirement that a database table contains Pega-specific columns. Unlike the PegaData and PegaRules schema tables where pzInsKey must be the primary key, a CustomerData schema table would never use it as the primary key. Since 7.3, Pega has a check box on the Rule-Obj-Class rule. When selected, Pega uses pyGUID as the primary key and automatically generates a value if the record being saved has not already received pyGUID a value.
Concrete data classes
The information within a “concrete” data class is meant to be persisted outside a case. It is permissible to copy concrete data into a case for historical data capture. When this copy occurs, the historical information is embedded within a case’s pzPvStream column, known as the BLOB. Historical data can also be stored outside a case BLOB. When this occurs, appending “-History” at the end of the data class name helps distinguish what the data class represents. There are benefits to storing data outside the BLOB from an inheritance and reporting standpoint instead of storing data within the BLOB then having to define a Declare Index to expose the data. The base of the Declare Index class would be Index-, not a Data-.
“Reference Data” is the name for a special type of data that, as the name implies, is persisted to be referenced. A possible use for Reference data is to populate the values for a drop-down list. In general, a Reference data class has no or very few references to other data instances.
From a packaging perspective, Reference data can be considered “atomic,” “self-contained,” “encapsulated,” or “dead-ended.” The network of data instances that reference each other can be packaged as a whole, then deployed to a different environment, initializing that environment before executing an application. An example of a network packageable, dead-ended data instance is FSG-Data-Address referencing FSG-Data-Location, which references FSG-Data-Contact. A Location is static information. A Location can be created at any time before it is used. Multiple Booking application BookEvent cases can reference the same FSG-Data-Venue instance. That Venue instance is then stored in the same CustomerData schema table as any other FSG-Data-Location instance.
An entire Reference Data instance should not be copied and persisted within a case’s BLOB unless there is a requirement. One reason to copy the data is that the values are transient (for example, price). Over time, the price for a product can change. A copy of the entire data instance can be made for historical auditing reasons.
If copying historical data, it is also important to persist the lookup values that were used to retrieve the data (that is, the reason why that particular data was accessed). For example, when an FSG-Data-Pricing record is persisted, not only is the ItemID, Reference, and Price information recorded, the inputs such as Quantity, Bit, and Discount Factor are also recorded. In this way, the same historical price can be re-derived in the future using those inputs. If in the future, an AsOfDate column is added to FSG-Data-Price, the FSG-Data-Pricing must record the date value it used when querying FSG-Data-Price. Copying an historical price is beneficial for performance reasons as doing so avoids having to perform the same calculations used to compute its value when the price was original stored. Imagine an invoice with numerous line items.
When no calculations are involved, it makes sense to do a Lookup (SOR Pattern) or JOIN from the case to the Reference Data instead of embedding it (Snapshot Pattern) in the case’s BLOB. An example is storing names. Names can change over time – Pega has no control over that. Pega does, however, have control over generated unique IDs. A name should not be used as a key. If performing a query based on a name, do not assume that a single row would be retrieved.
Abstract data classes
An example of an abstract class is the Component ruleset class, FSG-Data-Hotel-RoomsRequest, that the Hotel and HotelProxy applications share. Note that FSG-Data-Hotel is a concrete Reference data class defined at the Enterprise level. When using the Data Type wizard to define a new data type, it is possible to select one that already exists, including a concrete class. The Data Type wizard appends the name you enter, for example, “RoomsRequest” to the name of the existing class, for example, “FSG-Data-Hotel,” using a dash (“-“) as a separator. A pattern-inheriting class name is created.
FSG-Data-Hotel-RoomsRequest is never persisted because it is used purely for integration between the Hotel and HotelProxy applications. Storing a data instance in the Hotel application’s database does not benefit the HotelProxy application and vice-versa.
Another example where data is tightly coupled to the case (hence embeddable) is when the data class is virtually synonymous with the case itself. The purpose of the data class is to assist the case in performing its role of being a System of Record (SOR) for a transaction. The data class serves its purpose by providing reuse of certain rules such as sections, views, and data transforms. Multiple case types can use the same data class the same way (for example, as an abstract class).
Those multiple case types do not need to reference a concrete instance of that data class. The data class minimizes the number of case-level properties created. The greater the number of scalar properties that a case has, the more difficult it becomes to maintain the case (for example, what is scalar property X used for? What is scalar property Y used for?).
When multiple case types embed the same field group or field group list property it is tempting to move that property to the work pool class. This point is never reached if data model analysis is performed properly. Multiple case types using the same field group or field group list property is an indication that the property would likely be useful, as well, to sibling applications. It is a best practice to define the property within a built-on application. The opportunity to decompose the current application itself into sibling applications, built on a shared built-on application, was missed.
Law of Demeter
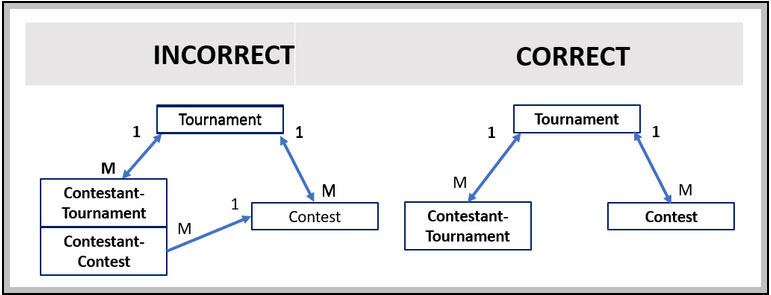
Contestants need a way to “play” each Contest within a Tournament. A concurrency issue would exist, however. Only one Contestant would be able update a Contest case at a time should a Contestant be allowed to access a Contest case directly. In addition to making security enforcement more complex, it is poor User Experience (UX) for a customer to be told that a case is locked, try again later.
Contestants could, instead, make their selections within an ORG-Data-Contestant-Contest instance. The -Contest portion of the class would be similar to a Link- class. A ContestRef property would point to the Contest case. A second property, ContestantRef, would point to the Contestant. According to the Law of Demeter, however, this is not incorrect.
The Law of Demeter says that redundant paths to the same object should be avoided. If the Tournament case were to remove a Contest, Contestant-Contest instances would still point to the removed Contest despite the Contest no longer being associated to the Tournament.
This scenario implies that a Tournament case should provide an “API” for Contestants to know what Contests are active.
A query would search for:
- Contestant-Tournament instances that both reference the Contestant and the Tournament case
- Contest instances where pxCoverInsKey equals the pzInsKey of the Tournament case
Enterprise-level versus application-level data classes
It is a best practice to define every data class that is central to how an organization does business at the Enterprise layer. Suppose a data class is central to an organization. In that case, a sibling application can likely be developed to use the same class. It does not make sense to force two Pega applications within the same organization to share information through integration and data transforms. The data class should be the same. This is no different than expecting every application to use Pega data classes such as Data-Party.
If an application has additional properties it wants to add to an enterprise-level data class (properties that do not apply to other applications), the application is free to directly inherit the enterprise-level Data class and then add those properties. According to the Open/Closed Principle, anything that works at the enterprise level should work equally at the application level from the enterprise application's perspective. The enterprise application does not care what specifically occurred at the application level; it only cares that functionality "X" was executed.
Occasionally, applications define data classes specific to that application and do not inherit a non-Pega data class that is defined in the reuse layer — this occurs when no other application needs to use the same data class.
Data class naming
It is common for a case to capture its primary payload (the data that the case manages) within a data structure synonymous with that class. While it is allowable for a case name to be a noun, in general, name a case based on action + noun or noun + action, such as BookEvent. This style applies because it is possible for the same noun, such as Event, to be processed by multiple case types. For example, EventBilling might be a second case type that operates against Event data.
It is unnecessary to append Details or Information to the noun that a case manages. The noun is a model of what an object is; its purpose is to encapsulate detail or information about a real-world object. You do not need to repeat this fact within the class name. Avoid redundancy.
It redundant and poor practice to repeat a property's owning class name within its name. For example, you do not name an FSG-Data-Event data class property EventStartDate. The fact that the property is related to an Event is understood. Name the property StartDate.
Likewise, the BookEvent case does not need an FSG-Data-Event EventDetails field group property. Event can suffice; no need to append Details.
Lastly, do not name the data class for that Event field group FSG-Data-EventDetails. The word "Details" does not add any value. Instead, Details makes the data model more challenging to comprehend. Appending Details suggests it is there for a reason. Is there another Event class that does not contain details? Name the data class FSG-Data-Event.
Data redundancy avoidance
Data integrity is about maintaining a Single Source of Truth, the practice of storing the same data in just one location, not two different locations. This principle is the reason behind database normalization techniques – first and foremost: “to free the collection of relations from undesirable insertion, update and deletion dependencies” (Edgar F. Codd, 1970). Suppose the same data, or a derivative of that data (such as Promoter Score Category) is stored in multiple places. What if the original data changes? Maintenance difficulty and complexity increase if an application is expected to keep track of and update every location where the same value is stored whenever the value changes. Imagine a Rule-Declare-Trigger having to deal with multiple locked instances simultaneously.
Data excellence webinar
Please refer the following link for additional details on data model : Data Excellence Webinar
If you are having problems with your training, please review the Pega Academy Support FAQs.
Want to help us improve this content?