データベースの問題の特定と診断
パフォーマンスに影響するデータベースの問題
アプリケーションにおけるデータベースのパフォーマンス問題の診断は困難な場合があります。 ほとんどのパフォーマンス問題は、アプリケーションにおけるデータベースの使用方法に原因があります。 データベースのパフォーマンス問題の根本原因を突き止めるには、データアクセスパターンやトランザクションの境界がデータモデルにどのように影響しているのかを分析します。
通常、データベースの問題はアプリケーションの実行速度に影響を与えます。 データベースの問題は、一般的にデータベーステーブルサイズ、BLOBの読み込み、不適切なSQLクエリーなどにより発生します。
ほとんどのパフォーマンス問題の原因は1つですが、時には2つ以上の原因によりパフォーマンス問題が発生することがあります。 例えば、解決済みのケースが多いモバイルアプリで、SQL接続は、大文字小文字を区別するフィールドのクエリーを、大文字と小文字を区別しないで実行することを求めます。
次のパフォーマンススナップショットの画像では、「+」アイコンをクリックすると、行われたすべてのデータベース関連操作に関する詳細が表示されます。
次の問題に答えて、理解度をチェックしましょう。
データベース問題の診断
データベースの問題は、多くの場合アプリケーションのパフォーマンス低下として現れます。 データベースの問題を診断する前に、症状を具体的に把握します。 パフォーマンス低下の報告を受けたユーザーから、低下する前の状況を説明してもらいます。 例えば、ユーザーは顧客からの問い合わせ画面を開いたときのみにパフォーマンスの低下を感じ、他のプロセスの速度は通常通りであるかもしれません。
データベースにおける問題に起因するパフォーマンス問題を診断するには、Dev StudioのPerformance Analyzer(PAL)を使用してパフォーマンスデータを生成します。 PALを実行し、画面ごとに段階的に読み取ることで、プロセスのどこで問題が発生しているかを特定し、そのステップの概要まで掘り下げていくことができます。 詳細については、「Tracking system utilization for a requestor session with Performance Analyzer」と「Using the full details display of Performance Analyzer」を参照してください。
補足: データベースのパフォーマンス問題の診断には、問題が発生しているユーザーのMy Performance Detailsレポートを確認することもできます。 My Performance Detailsレポートは、特定のセッションで特定のユーザーに起こったことをPALのようなスナップショットで表示します。 Dev StudioでConfigure > System > Performance > My Performance Detailsをクリックするとレポートが表示されます。 レポート上でオペレーターIDを変更すると、該当するユーザーのセッションデータが表示されます。
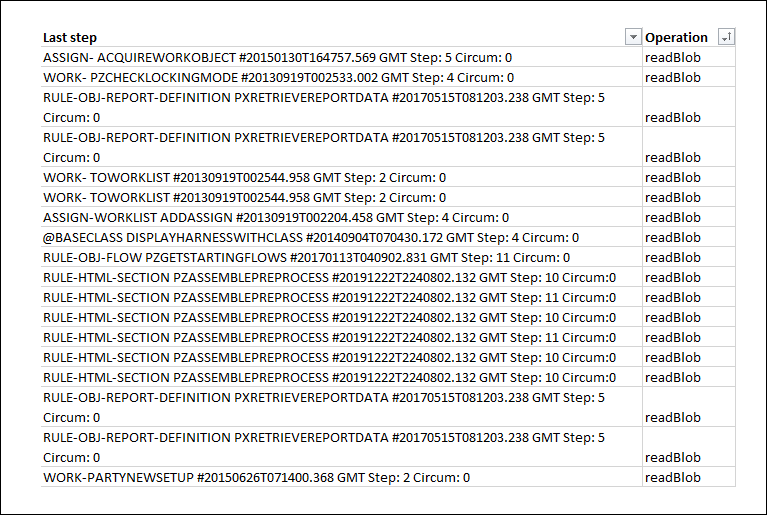
また、DB Traceを使って、データベースに対して行われたクエリーを調べることができます。 例えば、DB Traceの結果をReadBlobの操作でソートすると、BLOBからデータを読み込んだ操作を特定できます。 必ずアプリケーションルールセットでルールに注目してください。 次の画像は、すべてのreadBlob 操作を表示するDB Traceの結果です。
コンテキストに応じたパフォーマンスの統計を見ることができます。 また、どのくらいの頻度で、どのような状況で問題が発生するのかを特定する必要があります。 例えば、10,000件のインタラクションのグループで、しきい値を超えた45件のリクエストは、このインタラクショングループの0.5%未満です。 グループ内のインタラクションが70件であれば、同じしきい値を超える45件のインスタンスでも、重要度が高くなります。
下図はRequestor Summaryの例です。 サーバーインタラクションの数、データベースの時間しきい値、時間しきい値を超えたデータベースリクエストの数に注目してください。 この例では、データベースリクエストの約65%が時間しきい値を超えています。

補足: しきい値を超えた場合には、その都度アラートが表示されます。 アラートは違反を通知しますが、必ずしも原因を示すものではありません。
データベース問題の解決
データベースの問題は、大規模なデータベーステーブル、BLOBからの不要な読み取り、複雑なSQLクエリーなどにより発生します。 作業を開始する前に、Dev StudioのSystem Performanceランディングページにあるツールを使用して問題を診断します。
補足: プロパティを公開したり、データベーステーブルを新規作成してレコードを移動したりするなど、データベーススキーマを変更する場合は、事前にデータベース管理者(DBA)に相談してください。
大規模なデータベーステーブルによる問題
サイズの大きいデータベーステーブルは、そのボリュームがパフォーマンスに影響を与えます。 データベーステーブルが大きければ大きいほど、データベース上のデータにアクセスするのに時間がかかります。 例えば、ある保険会社は1日に数百件のクレームを処理します。 解決されるクレーム案件は膨大な数になります。 1年以内に、ケースワーカーが未解決のケースを検索する際の応答時間が通常よりも遅くなります。
サイズの大きいデータベーステーブルに対処するために、次のセクションで説明するPurge/Archiveウィザードの使用を検討してください。
サイズの大きいテーブルがクラスグループにマッピングされている場合、クラスグループ内の1つまたは複数のクラスのデータベーステーブルレコードを作成することを検討してください。 例えば、あるアプリケーションが5種類のケースを作成するとします。 作成されたケースの半分は、1つのケースタイプです。 最も使用されるケースタイプに別のデータベーステーブルを割り当てることで、クラスグループのテーブル成長率を低下することができます。 詳しくは、Working with class groupsをご覧ください。
テーブルがpr_otherの場合は、データベーステーブルレコードを作成して、1つ以上の特定クラスのインスタンスを別のテーブルにマッピングします。 これには、pr_otherから適切なテーブルにインスタンスを移動することも含まれます。 pr_otherテーブルを使用すると、PEGA0041アラートおよびガードレールアラートが発動するため、開発時に対処するのが最適です。
また、サイズの大きなデータベーステーブルは、リストレポートで問題を引き起こします。 リストレポートのページングを有効にして、レポートのパフォーマンスを向上させることができます。 ページングは、リストレポートが表示する結果の数を、設定した特定のページサイズに制限します。 また、ページングを行うことで、クリップボードのサイズが縮小され、各結果ページの表示にかかる時間も短縮されます。 ユーザーは次のページに移動して、他の結果を見ることができます。
データベースサイズに影響を与えるBLOBの問題
BLOBからの読み込みは、アプリケーションがBLOBを展開して必要なデータを取り出すためにメモリを割り当てる必要があるため、パフォーマンスに影響を与えます。 アプリケーションがBLOB全体を読み取り、展開し、必要なプロパティを抽出してからBLOBを破棄する必要があるリクエストは、データベーステーブルの列から値を読み取るリクエストよりも時間がかかります。

例えば、データページでは、ドロップダウンリストに表示する値のリストをデータベースに問い合わせるレポートディフィニッションを使用してデータを取得することができます。 BLOBに格納されたデータを読み取ると、クエリー時間が所定のパフォーマンスしきい値を超え、PEGA0005: Query time exceeds limitなどのパフォーマンスアラートが発生する場合があります。
BLOBの問題に対処する際の最初のステップは、プロパティが独自の列で公開する必要があるかどうかを判断することです。 BLOBからの読み取りによるパフォーマンスへの影響を評価するまでは、プロパティの公開は避けてください。 BLOBを使用すると、公開されていないデータを圧縮することで、テーブルの行のサイズを縮小することができます。 プロパティを不必要に公開すると、データベーステーブルのサイズが大きくなります。
Queryクエリーにおける問題
不正SQLクエリーは、Pegaが不必要にデータベースからアイテムを読み込まなければならないため、パフォーマンスに影響を与えます。 不正クエリーは、SQLコネクターまたはレポートで発生する傾向があります。 不要な大文字と小文字を区別するクエリーを実行するSQLルールがその例です。
DBTraceで特定のクエリーに時間がかかっていると報告された場合、SQLの構造に注目してください。 まず、DBTraceデータから置換値と一緒にクエリーをコピーします。次に、データベースのネイティブツールを使ってクエリーを分析し、最適化する方法を検索します。
| 発生する可能性のある問題 | 解決策候補 |
|---|---|
| contains条件を使用するSQLクエリー | starts withなどの、よりコストのかからない条件を検討する。 |
| SQLクエリーにinsertまたはupdateステートメントが含まれている | ストレージの最適化を検討する |
| 無関係なインデックス | インデックスの数が多すぎると、insert/updateステートメントが遅くなり、パフォーマンスが悪化することがあります。 必要なインデックスだけを使用してください。 |
| SQLクエリーによる2つのテーブルの結合 | Rule-Declare-Indexを作成してパフォーマンスを向上させます。これは、アクセス速度を上げるためにインデックスインスタンスを自動的に維持します。 詳細については、「About Declare Index rules」を参照してください。 |
Purge/Archiveウィザード
本番アプリケーションでは、ケースのデータ量が数百メガバイトのデータベースストレージを必要とするサイズにまで増大する場合があります。 Purge/Archiveウィザードでは、各テーブルから古いケースデータを自動的に削除し、オプションでアーカイブファイルに保存するバックグラウンドプロセスを設定し、実行計画を立てることができます。 ケースデータをアーカイブに保存することで、監査やバックアップの際にデータを取り込むことができます。 解決済みの古いケースと、それに関連する履歴や添付ファイルのレコードをパージすることで、データベースの処理要求を減らし、システムのパフォーマンスを維持することができます。
Purge/Archiveウィザードを使用する前に、アーカイブに保存するソースプロダクションシステムのコピー(同じルールとデータスキーマ)であるデスティネーションアーカイブシステムを確立します。 Purge/Archiveウィザードを使用するには、まずアクティビティを作成して、パージまたはアーカイブの基準を定義します。 そして、パージやアーカイブのアクティビティの予定を決めます。
削除されたレコードを復元する方法は簡単ではありませんので、パージのみのオプションを使用する場合は注意してください。
Purge/Archiveウィザードでレコードのアーカイブのみを設定することはできません。 パージは常にアーカイブの後に行われます。 アーカイブ後にパージすると、テーブルから行が削除されます。
詳細については、Pega Communityの記事「Purging and archiving old work items」をご覧ください。
次の問題に答えて、理解度をチェックしましょう。
トレーニングを実施中に問題が発生した場合は、Pega Academy Support FAQsをご確認ください。