ノード分類
Pega Platform™での処理は、クラスター内の個々のノードに分散させることができます。 Pega Platformは通常、ノードと呼ばれるサーバー上に配置され、ノードはクラスターと呼ばれるグループでまとまって機能します。 ノードは、ブラウザーのインタラクションを処理するためのリソースを提供し、バックグラウンドタスクやネットワークリクエストのリスニングなどのバックグラウンドプロセスを行います。
しかし、あまりにも多くのシステムリクエスター(ユーザー、バックグラウンドタスク、リスナーなど)が同じノード上で同時にタスクを実行しようとすると、アプリケーションのパフォーマンスが低下してしまいます。 リクエストされたタスクは、処理サイクルやデータベースへのアクセスを競合し、これがパフォーマンスの低下につながります。
システムプロセスやユーザープロセスを、ノードが実行するタスクの種類に応じて異なるノードに分配することができます。 この方法は、ノード分類と呼ばれます。 特定のタスクを特定のノードに割り当てることで、パフォーマンス上の問題を緩和することができます。 ノードにリソースを分散させることで、各ノードの処理負荷を軽減することができます。 例えば、ノード分類の手法を用いて、バックグラウンドプロセス用のノードと、ユーザー用のノードを指定することができます。
下図の「+」アイコンをクリックすると、ノード分類の概要が表示されます。
バックグラウンド処理を行うシステムのパフォーマンスは、作業がユーザートラフィックとは別のシステムで実行されるようにノードを分類するか、ユーザーが通常システムを使用していないときにバックグラウンド処理が行われるようにタイミングを合わせることで向上させることができます。 ジョブスケジューラーによる速度低下は、1日のうちの特定の間隔や特定の時間帯に周期的に発生する傾向があります。 ジョブスケジューラーをオフタイムに稼働させることが良い選択ではない場合もあります。 例えば、グローバルな組織で、ユーザーに常に優れたパフォーマンスを体験してもらいたい場合、システムに指定されたオフタイムはありません。 この場合、リソースを大量に消費するジョブスケジューラーやキュープロセッサー向けに特定のノードを分類することが最適な解決策になるかもしれません。
他にも、リスナーがランダムなタイミングでリクエストに応えることが多い例があります。 これらのリクエストは、大規模なファイルを処理し、膨大なデータベース操作を必要とするため、処理のネックになることがあります。 リスナーと同じノードで作業しているユーザーは、パフォーマンスの低下を感じる可能性があります。
補足: リスナーをノードに関連付ける方法に関しては「Associating listeners with node types」を参照してください。 キュープロッセッサーをノードに関連付ける方法に関しては「Node classification for Queue Processor rules」を参照してください。
次の問題に答えて、理解度をチェックしましょう。
ノードタイプによるノード分類
ノード分類では、目的に応じてノードを定義することができます。 ノード分類は、大きく分けて2つのタスクによって構成されています。
まず、アプリケーションサーバーでnode typesを設定して、ノードを分類します。 Pega Platformでは、ノードタイプはノードの目的を説明するJVMの引数です。 標準ノードタイプには、バックグラウンド処理、検索、ウェブユーザーなどがあります。 1つまたは複数のノードタイプでサーバーの設定を行うことができます。
補足: ノードタイプの作成方法に関しては「Creating node types for different purposes」を参照してください。
次に、Dev Studioでは、ジョブスケジューラーやキュープロセッサーまたはリスナーを特定のノードタイプに関連付けることができます。 例えば、ジョブスケジューラーとキュープロセッサーをSearchノードタイプに関連付けると、システムはSearchノードとして分類されたノードを使用します。
補足: キュープロッセッサーの作成方法に関しては「Creating a Queue Processor rule」を参照してください。Job Schedulerのルール作成ほうほ方法に関しては「Creating a Job Scheduler rule」を参照してください。
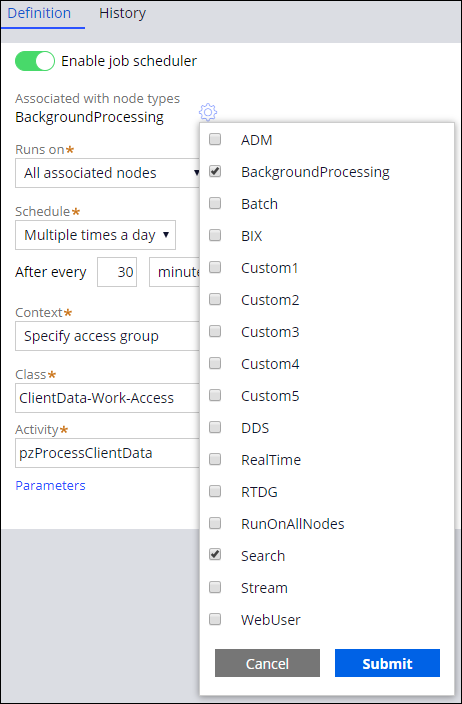
補足: クラスター内のすべてのノードが分類されている場合、ジョブスケジューラーやキュープロセッサーは、分類されたノードの少なくとも1つに関連付けられている場合にのみ実行されます。 クラスター内の分類されていないノードタイプにジョブスケジューラーまたはキュープロセッサーを関連付ける場合、ジョブスケジューラーまたはキュープロセッサーは、タイプ指定されていないノードのスケジュールに基づいて、タイプ指定されていないノード上で実行されます。 クラスター内のすべてのノードを分類し、ノードのスケジュールを一貫して管理することが奨励されます。
補足: ノード分類の詳細については「Classifying nodes」を参照してください。
トレーニングを実施中に問題が発生した場合は、Pega Academy Support FAQsをご確認ください。